Primeiros passos com Opentelemetry: Tudo (ou quase tudo) que você precisa saber
Sumário
- O que é o OpenTelemetry?
- Quais os componentes do OpenTelemetry?
- Tail Sampling Processor
- Segurança e dados sensíveis (PII não é opcional)
- Certificados, Keycloak e OpenID
- OpenTelemetry Collector Builder (OCB) e Load Balancing Exporter
- Cardinalidade: Os 10 mandamentos para quem começa
- Dica de ouro
Ao final da escrita me dei conta que fiz um tcc, por isso o sumário hahaha
O mundo da telemetria te oferece muitas possibilidades de coleta e transformação de dados. Antes de usar e listar pré-requisitos para começar a brincar nas instrumentações é importante saber a estrutura e objetivo do framework. Já deixo aqui meu profundo agradecimento ao Juraci Paixão Kröhling, Danilo Háwila e Marilya Gutierrez. São minhas referências de aprendizado contínuo com telemetria e indico totalmente para quem está começando.
Outra sugestão, caso se interessem é o livro Learning OpenTelemetry - Setting Up and Operating a Modern Observability System, foi escrito pelos co-fundadores Ted Young e Austin Parker do opentelemetry e tem uma linguagem muito bacana para explicar como os desafios foram pensados para que entenda como utilizar em aplicações modernas. Inclusive, irei apresentar insights referenciando-o nesse artigo.
1. O que é o Opentelemetry?
Trata-se de um framework de observabilidade, explicando for dummies, um esqueleto de código personalizável que irá receber telemetria, modificar, e enviar de forma segura para uma central de recebimento (backends como Grafana, Datadog, Dynatrace, Splunk, Jaeger…etc), que normalmente armazenam em um storage (s3, minIO, RustFs…) e possuem um frontend para tu criar alertas, dashboards, calcular sli, slo de forma correlacionada a fim de compreender o comportamento dos eventos gerados da sua aplicação. Utiliza o modo event-driven (envio por eventos) e seus dados são enviados em tempo real.
Uma analogia criada por Marilya Gutierrez para melhor fixação é o Cabo C, ele é universal para carregar diversos tipos de celulares (enviando telemetria para diversos tipos de backends) e possui o USB que seria sua aplicação enviando a telemtria. Isso revela o diferencial do OpenTelemetry, ser agnóstico. Ele é compatível com os backends de observabilidade tirando o lock-in, que é a venda de produtos com agents proprietários pagos. Caso queira mudar a solução, basta editar o apontamento e não fazer o retrabalho de tirar o agent e instrumentar novamente. Assunto sensível em aplicações críticas.
Para começar a diversão, segundo as definições de Ted Young e Austin Parker em 2024 na obra citad acima, temos os 3 pilares de observabilidade:métricas, logs e traces e cada um deles é composto pelas etapas abaixo, e dessa forma o opentelemetry se comporta:
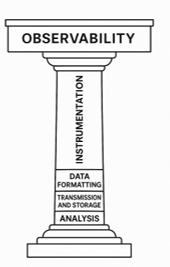
Fonte: Young, T., & Parker, A. (2024). Learning OpenTelemetry: Setting Up and Operating a Modern Observability System. O’Reilly Media. ISBN: 978‑1‑098‑14718‑1.
1.2 Quais os componentes do Opentelemetry?
1.2.1 Receivers
Os receptores ou Receivers como é chamado no bloco de código portão de entrada para recerber a telemetria. Quando for configurar o seu, olhe os modelos já prontos que a comunidade criou para facilitar seu processo https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver
Se o collector for local, define a porta e mantem o ip zerado
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
OTLP (OpenTelemetry Protocol) - Nativo
O OTLP é o padrão recomendado e nativo, projetado para interoperabilidade e eficiência.
Os formatos aceitos pelo coletor opentelemetry são:
-
gRPC: Geralmente usa a porta 4317. É preferencial para alto desempenho.
-
HTTP/Protobuf: Usa a porta 4318. Dados codificados em Protocol Buffers sobre HTTP.
-
HTTP/JSON: JSON sobre HTTP, facilitando a depuração, mas com maior overhead que Protobuf.
1.2.2 Processors
Eles são responsáveis por modificar ou transformar os dados antes de exportar para os backends.
1.2.2.1 Batch
O batch processor agrupa dados de telemetria (spans, métricas ou logs) antes de enviá-los aos exporters, reduzindo overhead e melhorando desempenho.
batch:
send_batch_size: 1000
timeout: 5s
Você pode definir o tamanho e o timeout.
- send_batch_size: Quantidade de itens no lote, atinge esse número ele envia imediatamente
- timeout: Tempo máximo de espera, mesmo que o batch não esteja cheio, ele envia
1.2.2.2 Span
O bloco span permite modificar, renomear, filtrar ou excluir spans antes que eles sejam exportados.
Lembrete: A configuração funciona apenas para traces.
Abaixo deixo 4 exemplos de como trabalhar:
# Exclusão de spans irrelevantes
span:
exclude:
match_type: strict
span_names: ["Transaction.commit"]
name:
from_attributes: ["resource.service.name"]
# Renomear spans
span:
- 'attributes["container.name"] == "app_container_1"'
- 'resource.attributes["host.name"] == "localhost"'
- 'name == "app_3"'
# Expressão de filtro OTTL = Aplique essa regra apenas se o span for gRPC E se o nome do span indicar que é gRPC.
spanevent:
- 'attributes["grpc"] == true'
- 'IsMatch(name, ".*grpc.*")'
# Extrair parte do nome do span e jogar em atributos
span:
name:
to_attributes:
rules:
- ^\/api\/v1\/document\/(?P<documentId>.*)\/update$
from_attributes: [db.svc, operation]
separator: '::'
1.2.2.3 Memory_limiter
O memory_limiter controla o uso de memória do Collector, limitando quanto de telemetria pode ser processada ao mesmo tempo para evitar OOMKill e instabilidade.
# A cada 5 segundos o Collector verifica o uso real de memória do processo.
memory_limiter:
check_interval: 5s
# Limite máximo de memória permitido para o Collector: ~2 GB
limit_mib: 2024
# Tolerância para picos rápidos de memória: ~1.5 GB
spike_limit_mib: 1500
Acima tem alguns parâmetros que pode definir, e vale salientar que nos casos de ter um collector por aplicação você poderá aplicar a regra de negócio.
1.2.2.4 Resource
Um dos blocos mais subestimados, mas ele revela sobre quem aquele evento está falando. Não só revela como utiliza de actions para proteger seus dados como hashs e deleta atributos irrelevantes.
Quando o trace te entrega um evento ruim na aplicação, ele responde as seguintes perguntas:
-
Quem gerou?
-
Em qual ambiente?
-
Em qual cluster?
Esse é um modelo que pode ser usado:
resource:
attributes:
# Cria o atributo hostname copiando o valor de host.name
- action: insert
key: hostname
from_attribute: host.name
# Cria o atributo container_name a partir de k8s.container.name
- action: insert
key: container_name
from_attribute: k8s.container.name
# Cria o atributo service_name copiando o valor de service.name
- action: insert
key: service_name
from_attribute: service.name
Um exemplo de como ficaria:
service.name=payment
deployment.environment=prod
k8s.cluster.name=eks-prod
Se faz importante alertar que é uma boa prática evitar colocar user.id, order.id, ou usar resource diferente para o mesmo serviço. Lembre-se que em larga escala manter um padrão fará diferença, pois precisará concatenar dados e usar regex no frontend da stack que irá trabalhar.(a maioria já faz insights automáticos)
Resource bem definido reduz cardinalidade sem perder contexto.
E falando em facilidades no frontend, eles são fundamentais para: agregação de métricas, definição de SLOs, filtros em traces e logs e custo (labels estáveis)
Cuidado ao colocar dado dinâmico em resource! Pode bagunçar sua visualização.
1.2.2.5 Attributes
São eles que contam a história certa! E os 3 pilares podem ser trabalhados com eles, logs, métricas e traces.
Span/traces
Dando contexto para um evento, por exemplo:
http.method = POST
http.route = /checkout
http.status_code = 500
db.system = postgres
Logs
Dando contexto ao log
level = error
user.role = admin
component = auth
Métricas
Dimensões de agregação
method = GET
status = 200
route = /checkout
Com eles você pode adicionar, remover, modificar, padronizar ou proteger dados sensíveis.
Através das funções de ação:
- insert
- delete
- update
- upsert
- hash
attributes:
actions:
# Insere o atributo resource.labels com o valor especificado, se ele ainda não existir.
key: resource.labels
value: hostname, container_name
action: insert
# Adiciona o atributo environment=production se ele ainda não existir.
- key: environment
value: production
action: insert
# Remove completamente o atributo db.statement do span/log/métrica.
- key: db.statement
action: delete
# Aplica um hash irreversível no valor do atributo email.(O dado continua existindo, mas não pode ser revertido para o valor original, usado para ofuscar valor irreversivelmente)
- key: email
action: hash
1.2.2.6 Filters
Outra chave poderosa do processor que decide quais dados continuam no pipeline e quais são descartados, com base em expressões OTTL. No modo for dummies ele corta dados na origem para reduzir ruído, custo e risco.
Destrinchando um exemplo:
# Data sources: metrics, metrics, logs
filter:
# Se uma expressão falhar, o Collector ignora o erro e segue o fluxo
error_mode: ignore
# Descartar spans que correspondam a qualquer uma dessas condições
traces:
span:
# Remove spans gerados por esse container específico
- 'attributes["container.name"] == "app_container_1"'
# Remove spans vindos de execução local (dev/test)
- 'resource.attributes["host.name"] == "localhost"'
# Remove spans com nome exato "app_3"
- 'name == "app_3"'
# Remove eventos de span (span events) relacionados a gRPC
spanevent:
- 'attributes["grpc"] == true'
- 'IsMatch(name, ".*grpc.*")'
# Essas regras filtram a métrica inteira
metrics:
metric:
- 'name == "my.metric" and resource.attributes["my_label"] == "abc123"'
- 'type == METRIC_DATA_TYPE_HISTOGRAM'
# Remove apenas pontos de dados específicos, não a métrica inteira
datapoint:
- 'metric.type == METRIC_DATA_TYPE_SUMMARY'
- 'resource.attributes["service.name"] == "my_service_name"'
logs:
log_record:
# Remove logs que contenham a palavra password.
- 'IsMatch(body, ".*password.*")'
# Remove logs de nível:DEBUG e INFO
- 'severity_number < SEVERITY_NUMBER_WARN'
1.2.3 Exporters
O ponto agnóstico do nosso cabo C. É aqui que você poderá definir quem irá receber sua telemetria.
exporters:
# Imprime a telemetria no log do Collector, excelente para debug de pipeline, validação de processors, testes locais
debug:
verbosity: detailed
otlp:
# Envia telemetria via protocolo OTLP para outro Collector ou backend compatível
endpoint: otelcol2:4317
# Habilita comunicação segura (mTLS).
tls:
cert_file: cert.pem
key_file: cert-key.pem
# Envio de métricas
prometheus:
endpoint: 0.0.0.0:8889
namespace: default
# Envio de traces
zipkin:
endpoint: http://zipkin.example.com:9411/api/v2/spans
# Envio de logs
otlphttp/logs:
endpoint: LOGS_URL
tls:
insecure: true
Eu sei que você viu sobre o tls, mas falaremos disso já já.
1.2.4 Connectors
São componentes que consomem um tipo de sinal e produzem outro tipo de sinal, conectando pipelines diferentes. Pode consumir dados como exportador no final de um pipeline e emite dados como receptor no início de outro pipeline.
Ficou confuso? segue exemplo:
connectors:
count:
# Aqui eu concateno a contagem do meu atributo
spanevents:
my.prod.event.count:
description: Contagem de spans que tem no meu ambiente de prod.
conditions:
- 'attributes["env"] == "prod"'
- 'name == "prodevent"'
Com eles você pode dar profundidade ao seu evento, mas lembre que o básico bem feito entrega valor e aqui uma conexão de span mal tratado só irá amplificar o problema. Pois aqui os traces viram métricas.
1.2.5 Extensions e Services
Enquanto em services tu irá listar quais recursos seu coletor vai usar, seria como um resumo, mas se habiitar a função e não colocar nele, nada feito.
service:
extensions: [health_check]
pipelines:
traces:
receivers: [otlp]
processors: [span,batch]
exporters: [otlp]
logs:
receivers: [otlp]
processors: [resource, attributes, memory_limiter]
exporters: [otlphttp/logs]
metrics:
receivers: [otlp,prometheus]
processors: [batch]
exporters: [prometheusremotewrite]
Nas extensions, você irá utilizar “plugins” numa linguagem mais informal para interagir com seu collector.
O que as extensions fazem na prática?
-
Observam o próprio Collector: health check, status, diagnóstico
-
Controlam acesso: autenticação, autorização, segurança de endpoints
basicauth:
client_auth:
username: user
password: pass
-
Ajudam no debug: profiling, métricas internas,ZPages
-
Integram com o ambiente: kubernetes, cloud, certificados, configuração dinâmica
extensions:
# Exponde endpoint /health, indica se o Collector está vivo
health_check:
endpoint: 0.0.0.0:13133
# Debug de performance, diagnóstico de vazamento de memória
pprof:
endpoint: 0.0.0.0:1777
# Entender gargalos no Collector, troubleshooting em tempo real
zpages:
endpoint: 0.0.0.0:55679
1.3 Tail Sampling Processor
O tema mais polêmico e que faz total diferença financeira e qualitativa dos seus dados de telemetria. O Tail Sampling Processor decide se um trace inteiro será mantido ou descartado somente depois que ele termina.
Ele observa o trace inteiro e toma decisões como: “Esse trace teve erro?”, “Esse trace foi lento?”, “Esse trace passou por uma rota crítica?”, “Esse trace veio de um serviço importante?”
Se sim, ele mantém.Se não, ele pode descartar.
1.4 Funções
Você pode conferir elas aqui: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/tailsamplingprocessor/README.md
Parâmetros que são ponto de atenção no arquivo de configuração:
# Tempo máximo que o Collector espera para decidir.
decision_wait: 30s
# Quantidade máxima de traces mantidos em memória para decisão.
num_traces: 50000
Como ele funciona por policies(Políticas utilizadas para tomar uma decisão de amostragem), vão aqui alguns exemplos:
1.4.1 Policies: As que mais gosto
- drop: Excluir (não amostrar) com base em várias políticas, cria uma política DROP
# Quando houver valores com health no url.path deverão ser excluídas
{
name: drop-policy-example-1,
type: drop,
drop: {
drop_sub_policy:
[
{
name: test-drop-policy-1,
type: string_attribute,
string_attribute: {key: url.path, values: [\/health], enabled_regex_matching: true}
}
]
}
}
- status_code: baseado no status code (OK, ERROR or UNSET)
# Mostra todos com erro
{
name: statuscode-policy-01,
type: status_code,
status_code: { status_codes: [ERROR] }
- latency: Seleciona os traces lentos com latência predefinida pelo threshold_ms.
# Guardar apenas quando os traces tiverem dentro desse intervalo de latência
{
name: latency-policy,
type: latency,
latency: {threshold_ms: 8000, upper_threshold_ms: 10000}
}
- probabilistic: Entrega uma amostragem dos dados
# Mostra 5% dos traces saudáveis
- name: probabilistic
type: probabilistic
probabilistic:
sampling_percentage: 5
- filter by rout
# Filtragem pela rota de checkout e pagamentos, finalização de um pedido quando falamos de ecommerce.
name: critical_routes
type: string_attribute
string_attribute:
key: http.route
values: ["/checkout", "/payment"]
Logo, o sampling mantém traces realmente úteis e reduz o tráfego irrelevante que sobe no backend.
1.5 Segurança e dados sensíveis (PII não é opcional)
Se você não trata segurança na origem, você está criando um data lake de risco.
1.5.1 PII (Personally Identifiable Information)
O PII são informações que identificam uma pessoa, logo todos os dados sensíveis que aparecem na telemetria precisam ser tratados a fim de LGPD para garantir a segurança das informações. Podem aparecer nas métricas, logs e traces.
Alguns exemplos:e-mail, CPF / documento, IP do usuário final, user_id, session_id, tokens de autenticação, dados de saúde, dados financeiros.
1.5.2 Hash
A função hash transforma um valor sensível em um identificador irreversível.
Exemplo de como fazer:
processors:
attributes/hash_pii:
actions:
- key: email
action: hash
Como ficaria:
email = lara@empresa.com
↓
email = a94a8fe5ccb19ba61c4c0873d391e987
1.5.3 Regex
Usa de expressões regulares para identificar e tratar padrões sensíveis.
Exemplo de como fazer:
processors:
filter/logs_pii:
logs:
log_record:
- 'IsMatch(body, ".*password.*")'
- 'IsMatch(body, ".*token.*")'
.*password.*
.*token.*
.*authorization.*
1.5.4 Delete
Remove completamente o dado sensível.
- key: db.statement
action: delete
Removendo headers sensíveis:
processors:
attributes/delete_headers:
actions:
- key: http.request.header.authorization
action: delete
- key: http.request.header.cookie
action: delete
1.6 Certificados
Aproveitando o gancho de segurança, é possível usar certificados TLS nos receivers e exporters para assegurar seus dados. E também Keycloak + OpenID / OAuth2 para casos de ambientes multi-tenant (segregação de quem pode ver os dados de telemetria baseados em grupos de autenticação com usuário, senha e 2FA). Trarei isso em um outro artigo com passo a passo, mas tem bastante conteúdo sobre.
1.7 OpenTelemetry Collector Builder (OCB) e Load Balancing Exporter
1.7.1 OpenTelemetry Collector Builder (OCB)
O OCB permite criar uma versão customizada do Collector, contendo apenas os componentes que você precisa, ou seja, você pode criar o seu próprio binário. Ele é excelente para padronização e essa dica eu vi com o Juraci!
Normalmente, o Collector oficial vem com: dezenas de receivers, dezenas de processors,dezenas de exporters. E isso acaba gerando um binário maior, superfície de ataque maior, mais dependências e consequentemente mais overhead.
Com ele você tem algo padronizado, enxuto com superfície de ataque menor! Se você não usa um componente, ele não deveria estar no seu binário. E, caso tenha ficado dúvida sobre qual usar, o Core, Builder ou Contrib…tem esquema de comparação:

Contrib é para experimentar, Core é para aprender, OCB é para operar.
1.7.2 Load Balancing Exporter
O load balancing exporter distribui traces entre múltiplos destinos, garantindo que todos os spans de um mesmo trace cheguem ao mesmo backend.
Link do projeto: https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/loadbalancingexporter
Se torna crítico para traces distribuídos,tail sampling, backends como Tempo / Jaeger porque traces não são dados independentes. São conjuntos de spans que precisam se encontrar no mesmo lugar.
As opções para routing_key são: service, traceID, metric(nome da métrica), resource, streamID
Ele calcula hash do trace_id, escolhe um backend consistente e garante afinidade do trace.
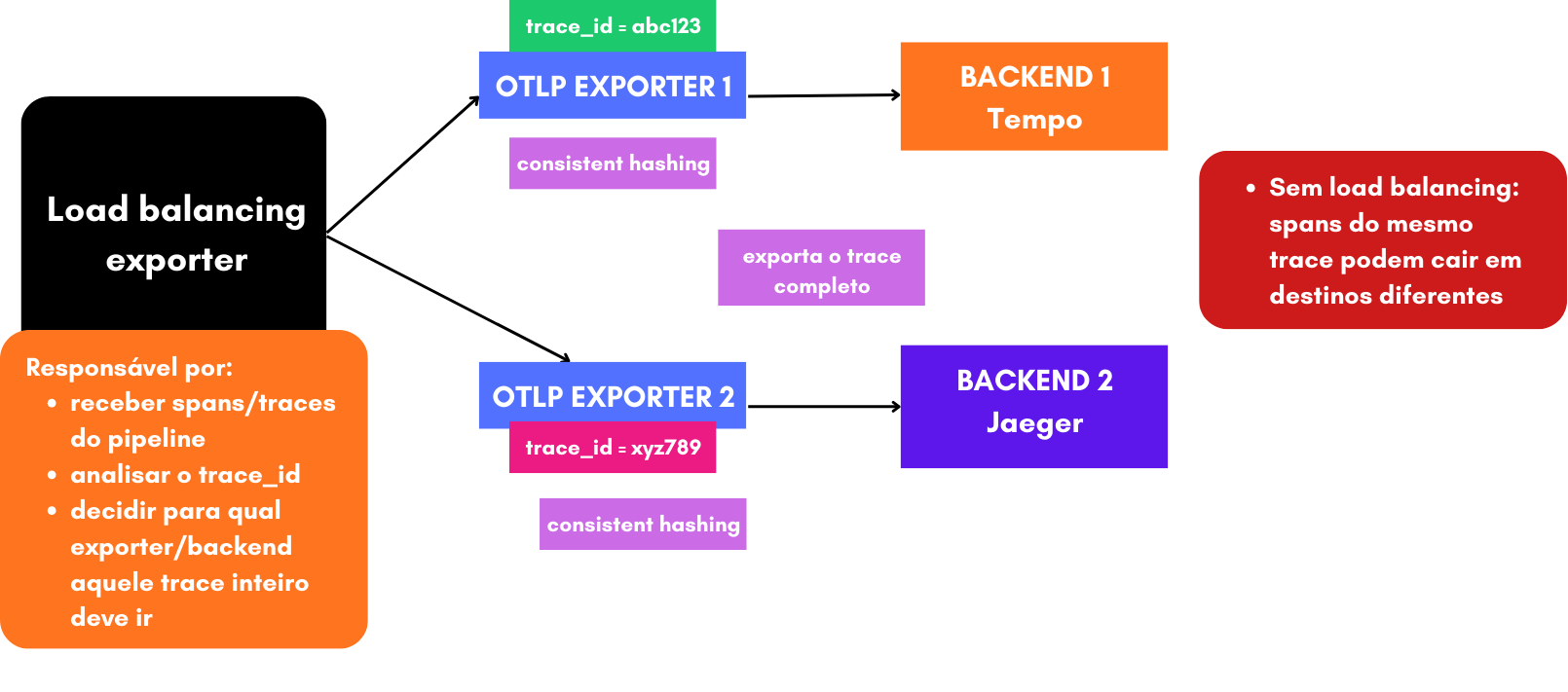
Load balancing em observabilidade não é sobre distribuir carga, é sobre preservar contexto ao decidir para qual backend um trace completo deve ir.
1.8 Cardinalidade: o erro mais comum de quem está começando
Como já tivemos muita informação até aqui, criei os 10 mandamentos da cardinalidade para ajudar a memorização!
1. Não criarás labels infinitos
Se o valor pode crescer sem limite, ele não é um label. user_id, order_id, session_id não pertencem a métricas.
2.Não confundirás detalhe com valor
Mais informação não é mais observabilidade. Detalhe demais = ruído.Ruído demais = cegueira.
3. Honrarás o resource, pois ele é estável
Identidade vem de resource, não de atributo dinâmico. Se muda a cada requisição, não é identidade.
4. Santificarás as rotas
URL dinâmica não é rota, é armadilha. /order/983742 é um ataque silencioso à sua stack. Normalize ou pague a conta.
5.Eliminarás o que não investigas
Se você nunca usa esse campo para investigar um incidente, ele não deveria existir. Observabilidade não é arqueologia.
6.Protegerás PII como se fosse produção (porque é)
Telemetria também é dado sensível. Se vazar, o problema é seu, não da ferramenta.
7.Hashearás antes de indexar
Correlação sem exposição é maturidade. Se precisa identificar, hasheie.Se não precisa, delete.
8.Não sacrificarás o backend
Métricas ruins derrubam sistemas bons. Prometheus, Mimir, Tempo e Loki não quebram sozinhos.Eles quebram porque alguém colocou order_id como label.
9.Tratarás cardinalidade antes de escalar
Escalar uma stack sem controlar cardinalidade só aumenta o prejuízo. HA não resolve erro conceitual.
10. Lembrarás: observabilidade é decisão
Cada atributo é uma escolha. E toda escolha tem custo, impacto e responsabilidade.
1.9 Dica de ouro
Falando em cortar custos e dados que não servem, já pensou em cortar esses logs de health e validações da sua telemetria? Corte parte do volume de logs que chegam no seu colector para ter uma visão mais limpa e menos ingest.
Esse artigo aqui é ouro: https://opentelemetry.io/blog/2026/log-deduplication-processor/
Era pra ser os primeiros passos, mas imagino que já dá pra fazer uma boa caminhada! hahaha