Tracing forense: Grafana Tempo distribuído como o CSI de observabilidade
Quando o assunto é tracing distribuído, o Grafana Tempo é aquele agente que chega de terno e gravata na cena do crime. Cada componente tem um papel específico, e juntos eles reconstroem a linha do tempo do incidente.
A analogia CSI do Grafana Tempo
Na imagem abaixo, transformei os componentes do Grafana Tempo distribuído em personagens de uma investigação forense:

Distributor → O policial de patrulha
Recebe as pistas (spans) e distribui entre os investigadores corretos.
“Você cuida da cena do servidor A, você do servidor B.”
Ingester → O investigador
Analisa rapidamente as pistas e registra temporariamente antes de enviar para o arquivo de provas.
“Anota aí: requisição começou às 14h03.”
Backend / Block Storage → O arquivo de provas
Guarda todos os traces arquivados para revisitar quando necessário.
“As evidências estão guardadas na sala 3.”
Querier → O detetive principal
Recebe o pedido de investigação:
“O que aconteceu com o pagamento de ontem?”
Ele consulta as provas e reconstrói a linha do tempo.
“Achei o culpado: timeout na API.”
Query Frontend → O sargento organizador
Gerencia as solicitações para que a equipe não se perca.
“Você investiga esse caso, você aquele.”
Compactor → O arquiteto de caso
Agrupa eventos antigos e mantém só o essencial para economizar espaço.
“O relatório final já está resumido, pronto para arquivar.”
O que o Grafana Tempo faz (de verdade)
O Grafana Tempo é um sistema de distributed tracing backend: ele coleta, armazena e busca traces de aplicações distribuídas.
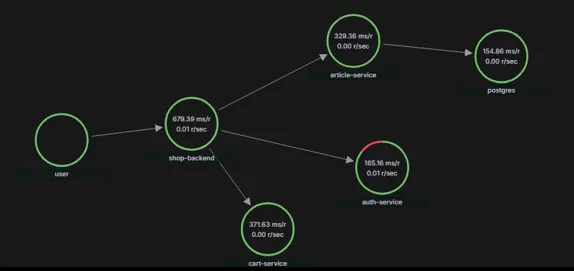
Ele monta através do service graph o desenho de interações da aplicação, automaticamente.
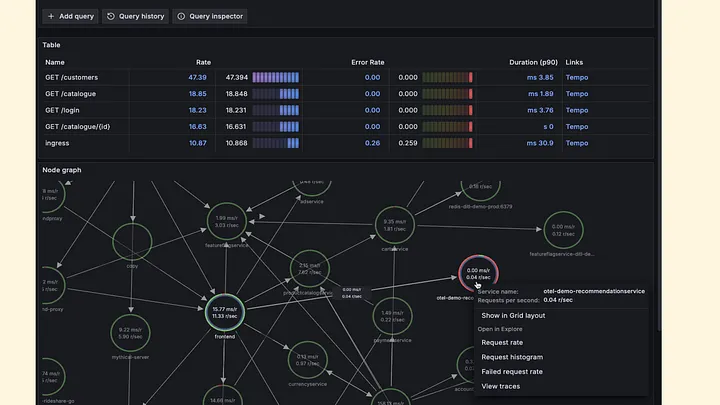
E ao correlacionar os datasources em sua configuração, ele passa a exibir métricas e logs relacionados ao evento.
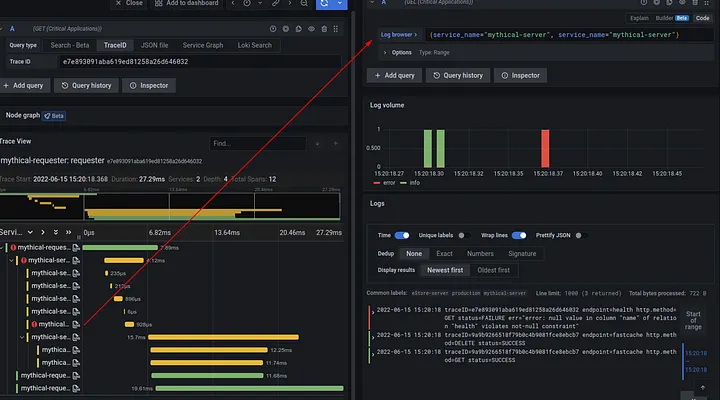
Foi desenhado para:
- Armazenar traces em backends de objeto (S3, MinIO, GCS, etc.);
- Escalar horizontalmente sem um banco de dados tradicional;
- Integrar nativamente com Grafana, Alloy, OpenTelemetry Collector, e Loki.
Pontos fortes
- Escalabilidade: feito para lidar com bilhões de spans.
- Integração nativa com todo o ecossistema Grafana.
- Custo reduzido graças ao uso de storage de objeto.
- Performance alta na consulta e compressão.
- Ideal para arquiteturas de microserviços e ambientes multi-tenant.
Desafios
- Sem UI própria — depende do Grafana para visualizar.
- Curva de aprendizado alta para quem vem de Jaeger.
- Arquitetura distribuída exige atenção na orquestração (Compactor, Querier, etc.).
- Retenção e compactação mal configuradas podem gerar “cold cases” difíceis de reabrir.
Quando usar (e quando não)
Use o Grafana Tempo quando sua prioridade for escala e custo. Ele brilha em ambientes cloud-native, integrados ao OpenTelemetry, e com volume massivo de dados.
Mas se o objetivo for aprendizado, debug simples ou times em início de maturidade, o monolito do Grafana Tempo ou Jaeger ainda é mais indicado.
O Grafana Tempo é o laboratório forense da observabilidade. Ele não só coleta os rastros, mas reconstrói o passado de forma precisa. Com o uso da stack completa a correlação ainda se torna melhor.