Entendendo Correlações, SLA, SLO e o Papel do SRE: Uma releitura da Engenharia de Confiabilidade do Google
A confiabilidade de sistemas distribuídos é uma das maiores preocupações para empresas que escalam suas operações digitalmente. Em um mundo onde a disponibilidade e a experiência do usuário são fatores críticos, termos como SLA , SLO e SRE ganham importância estratégica. Neste artigo, faço uma releitura dos capítulos 10 e 12 do renomado livro Site Reliability Engineering , do Google, destacando os principais conceitos de demonstração, acordos de serviço e o papel do SRE nesse cenário.
O que é SRE?
SRE (Site Reliability Engineering) é uma abordagem que aplica princípios de engenharia de software para resolver problemas operacionais de infraestrutura. Criado pelo Google, o SRE busca equilibrar a velocidade de entrega de novas funcionalidades com a estabilidade dos sistemas em produção.
Entendendo SLA, SLO e SLI
Esses três termos são comumente confundidos, mas possuem significados diferentes e complementares:
SLA (Service Level Agreement) é o contrato firmado com os clientes, geralmente externo, e define como garantias formais de disponibilidade ou desempenho. SLO (Objetivo de Nível de Serviço) é um objetivo interno mensurável, previsto para garantir que os serviços mantenham a confiabilidade desejada. SLI (Service Level Indicator) são as métricas reais que medem a qualidade do serviço (como latência, taxa de erros, disponibilidade).
O SRE utiliza esses conceitos para construir sistemas mais resilientes, com monitoramento adequado e tolerância a falhas.
Como criar SLAs e SLOs?
Diferença Chave: SLA (Acordo com o Cliente) : Exemplo: “Disponibilidade de 99,5% ao mês ou lucro financeiro.”
SLO (Objetivo Interno) : Exemplo: “Disponibilidade de 99,9% para evitar riscos ao SLA.”
5 Passos para Definir SLOs Eficientes
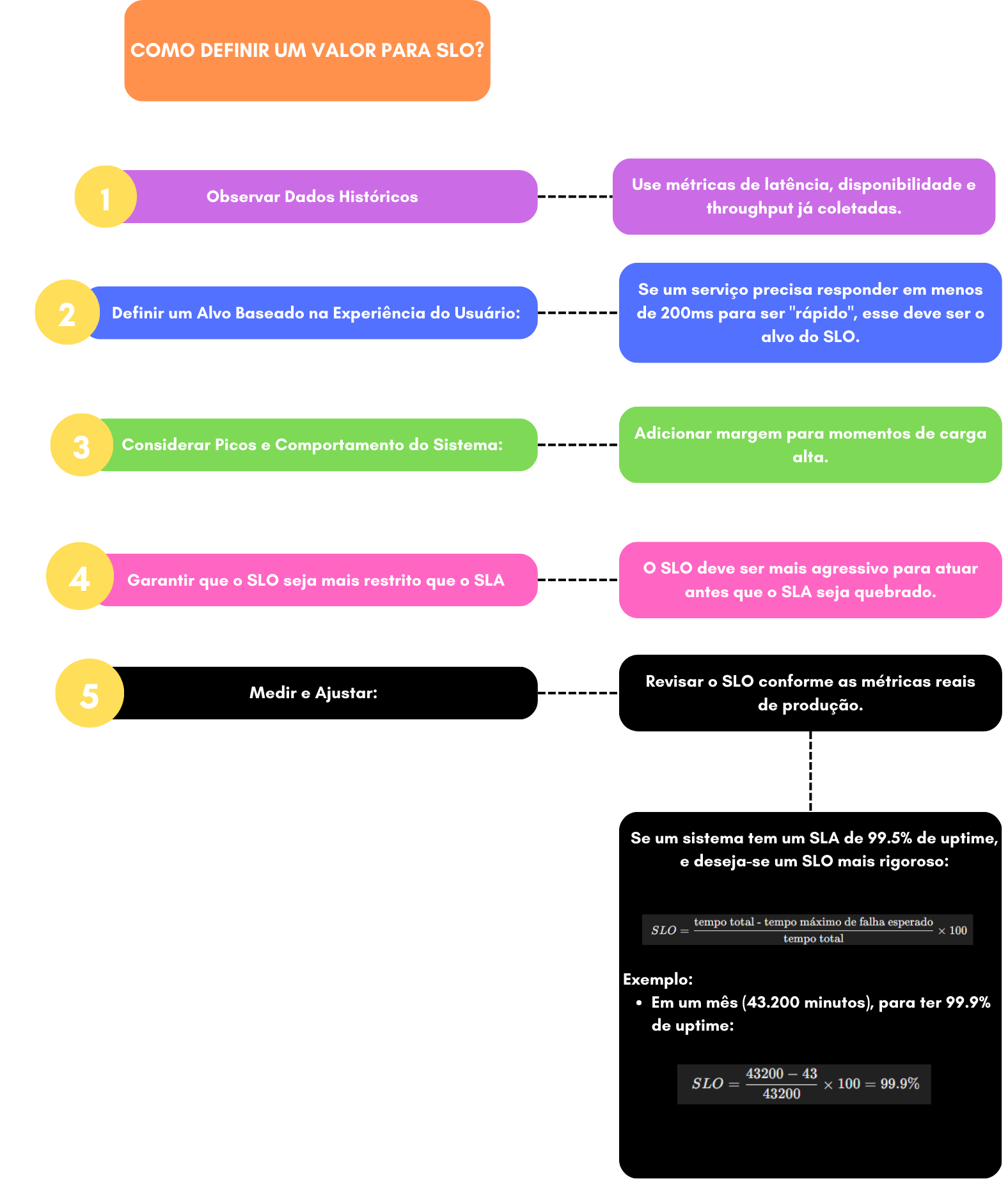
Observe o Comportamento Real do Sistema : Ex.: Se 95% das requisições têm latência < 200ms, esse é um bom candidato a SLO.
-
Alinhe com a Experiência do Usuário : Ex.: Um e-commerce define SLO de latência com base no abandono de carrinho .
-
Considere Custos e Complexidade : Manter 99,99% de disponibilidade pode ser 10x mais caro que 99,9%.
-
Garanta que o SLO Seja Mais Rigoroso que o SLA : Se o SLA for 97,5%, o SLO deve ser 99% para criar uma zona de segurança .
-
Revisar regularmente : os SLOs devem evoluir com as mudanças no produto e na infraestrutura.
Exemplo Prático de Cálculo :
Para um serviço com SLA de 99,9% em um mês (43.200 minutos):
- Tempo de Inatividade Aceitável : 43,2 minutos.
- SLO Interno : 99,95% (21,6 minutos de margem).
Caso Prático: Alerta à Solução
O processo de definição de SLIs e SLOs geralmente segue um fluxo estruturado. Tudo começa com a identificação de um problema, seguida por uma triagem e análise detalhada — muitas vezes utilizando ferramentas específicas e a técnica dos “5 porquês” para investigar a causa raiz. A partir desse diagnóstico, é possível entender os fatores e processos que desenvolvem para a falha e, com isso, propor testes e tratamentos preventivos, caso o problema volte a ocorrer. Em seguida, a solução é documentada, e são criados alertas e dashboards para monitoramento contínuo. Nesse estágio, os SLOs e SLAs se tornam fundamentais, pois orientam a priorização das investigações e ajudam a evitar decisões contratuais, especialmente em serviços considerados críticos.
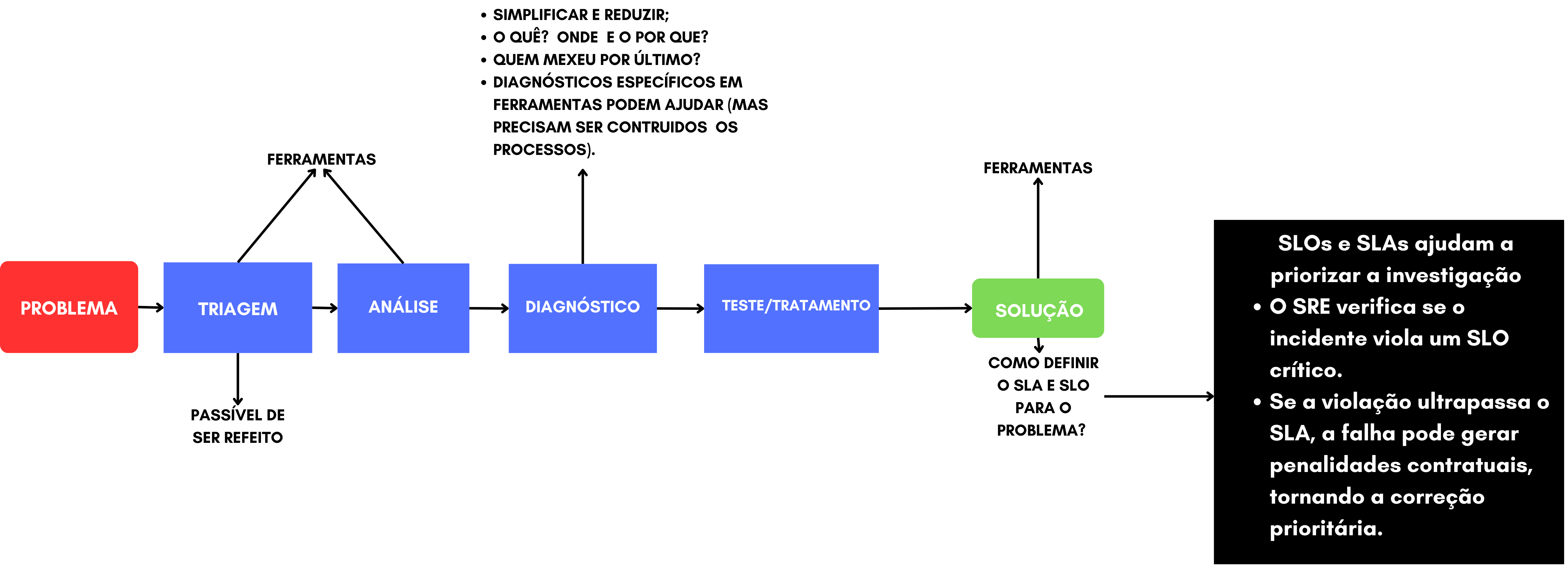
Caso 01 para ilustrar a explicação:

1. O Problema
O horário de monitoramento notificou que um servidor de aplicação estava reiniciando intermitentemente.
2. A Triagem e Análise
O SRE analisou:
- Logs do sistema operacional : Picos de consumo de memória antes de cada reinício.
- Métricas de aplicação : Aumento contínuo no uso de RAM sem liberação (possível vazamento).
- Logs de aplicação : Conexões HTTP não fechadas corretamente.
3. O Diagnóstico
Identificou-se que:
*“Um vazamento de memória ocorria devido a conexões HTTP persistentes não finalizadas, fazendo o sistema operacional matar o processo (OOM Killer).”*
4. A Solução
- Ajuste no coletor de lixo da aplicação.
- Correção do código para fechar conexões HTTP.
- Implementação de alertas proativos para consumo anormal de memória.
**Lição:** Monitorar apenas “CPU alta” não basta. É preciso correlacionar logs, análises e rastreamentos para entender a causa raiz.
Caso 02 com sugestões de SLO
1. O Problema
Imagine que você está usando um aplicativo, mas ele está lento . Algumas páginas demoram para carregar. Isso irrita, né? Pois é, outros usuários também reclamaram disso.
2. Triagem e Análise
Um técnico chamado SRE (Site Reliability Engineering) , que é responsável por garantir que o sistema funcione bem, iniciou uma investigação. Eles fizeram isso em etapas:
Verifiquei alertas : Notaram que muitas requisições estavam demorando demais e até travando (timeout). Olharam os gráficos do sistema : Perceberam que o banco de dados (onde ficam guardados as informações) estava sendo muito usado e com lentidão.
Analisaram as consultas : Descobriram que os comandos usados para buscar dados (as consultas SQL) estavam demorando muito. Viram outros possíveis problemas : Como outras partes do sistema que estavam sobrecarregadas ou falhando.
3. Diagnóstico e Solução
Depois de entender o problema, o tempo fez algumas coisas para resolver:
-
Melhoraram o banco de dados : Colocaram índices para deixar as buscas mais rápidas.
-
Evitaram buscas repetidas : Usaram uma técnica chamada caching que guarda os dados mais usados para não ter que buscar no banco toda hora.
-
Criaram alertas inteligentes : Para avisar se a lentidão acontecer de novo no futuro.
4. Como criar indicadores a partir disso?
SLIs: São as métricas que medem a qualidade do serviço. Na imagem, temos como SLI:
-
Tempo de resposta de requisições HTTP
-
Percentual de requisições atendidas em menos de 200ms
-
Uso de CPU e memória do banco de dados
-
Latência de consultas no banco de dados
-
Taxa de erros (timeouts, falhas de cache, falhas de dependências externas, etc.)
SLOs:
São os alvos ou metas internacionais que queremos atingir com base nos SLIs. Os SLOs definidos na imagem incluem:
-
99% das requisições devem ser atendidas em menos de 200ms
-
O tempo médio de resposta do banco de dados deve estar abaixo do limite X (implícito) — usado para verificar se o SLO está quebrado
-
95% das requisições devem ser respondidas em menos de 200 ms , caso o SLA permita menos desconforto
-
Erros ou lentidão que ultrapassem a margem de erro do SLO precisam ser tratados imediatamente
SLA:
-
Tempo de atividade mínimo de 99,95%
-
Se o serviço ficar fora do ar mais de 3h36min no mês, há violação contratual e possível retorno financeiro
Hora da dica: Entendendo a Relação entre Métricas
Um ponto interessante discutido nos capítulos do livro é um esclarecimento entre detalhes . Nem sempre dois eventos correlacionados indicam causalidade, mas entender essas relações ajudam na construção de alertas mais identificados e na identificação de anomalias reais.
Por exemplo, um aumento na latência pode estar correlacionado a um pico de tráfego. Entretanto, uma experiência SRE sabe que não há significado significativo, e por isso investigue os dados com cuidado antes de tirar conclusões.
Como o SRE Usa Esses Conceitos na Prática
O engenheiro de confiabilidade utiliza SLIs para medir o comportamento dos serviços e comparar esses indicadores com os SLOs definidos. Quando um SLO estiver próximo de ser violado, o tempo poderá pausar novas implementações para evitar riscos de confiabilidade.
Além disso, o erro orçamentário é uma ferramenta poderosa do SRE. Ele define quanto de “erro” é aceitável dentro de um determinado período. Esse orçamento de erro permite inovar com segurança, sabendo quanto o sistema pode falhar sem comprometer o SLA.
Seu tempo já teve um problema ‘técnico’ que virou um problema financeiro?