Você sabe o que fazer com Error Budget e MTTR?
Esses dois sinais são os mais sensíveis para decisões estratégicas de negócio. Saber quando investir na equipe ou em recursos é uma métrica que a observabilidade entrega, mas não basta tê-las se não souber o que fazer depois.
Partindo do pressuposto que a maioria das equipes de monitoramento são mais reativas e se concentram em resolver o problema ao invés de análisar de forma macro como poderia ser solucionado de forma permanente, alguns gestores também não conhecem como usar isso para planejar suas implantações e garantir a confiabilidade com sua equipe.
O Error budget normalmente é acompanhado dos cálculos de SLI, SLA e SLO e significa o tempo de erro aceitável para indisponibilidade. Logo, se eu quero uma disponibilidade do meu serviço de 99% em 7 dias (SLO), eu tenho 1% de margem caso aconteça algo: uma atualização, travamento, subida de recursos para não pagar as multas de acordo (SLA). o SLI calcula o quanto ele ficou disponível em um determinado tempo concatenando os serviços principais que acarretem a queda.
Outro exemplo:
SLO: 99,9%
Error Budget: 0,1%
Janela mensal → ~43 minutos de erro aceitável
Error Budget responde: quanto risco aceitamos
MTTR responde: quão rápido aprendemos
Mas, vale lembrar que também não é uma licença para errar. Se está nesse papel de “Ainda temos budget, pode deployar” ou “Estourou o budget, congela tudo”, tem algo errado ocorrendo.
Ele serve para priorizar trabalho, negociar risco com negócio e equilibrar inovação vs estabilidade.
Como por exemplo:
Budget saudável → foco em features
Budget em risco → foco em: performance, resiliência, débito técnico
O MTTR é o tempo médio de recuperação desses incidentes/alertas até sua resolução. Ele releva duas coisas importantes, recorrência e duração.
Ao calcular, essas perguntas devem ser respondidas:
-
Quem? - nome do host
-
Quantas vezes? - recorrência
-
Quando durou? - segundos, minutos, horas, dias
-
Qual o período? semanal, mensal, anual
Isso acaba evidenciando falta de visibilidade, runbooks ruins, alertas pouco acionáveis.

Error Budget estourou?
Checklist prático:
-
Não caçar culpados
-
Post-mortem sem blame
Revisar:
- Alertas
- SLO
- Arquitetura
- Capacidade
Sintomas de não estar atento a esses sinais
-
Incidente = custo
-
MTTR alto = custo prolongado
-
Error Budget mal gerenciado = mais retrabalho, mais horas humanas, mais infra emergencial
**Dica:** Para começar a ver isso, colete essas informações e conecte com: custo por indisponibilidade, custo por time envolvido, custo por cliente perdido. Assim terá uma dimensão melhor.
Quando NÃO usar Error Budget
-
Sistemas regulados (saúde, financeiro crítico)
-
Ambientes sem SLO definido
-
Times ainda sem cultura de post-mortem
Dica de ferramenta para orientar seu time a entregar essas informações
Zabbix
1. Observe o Top 100 de triggers (Para ter dimensão de recorrência de alertas numa forma geral durante o período de dias, meses, anos)
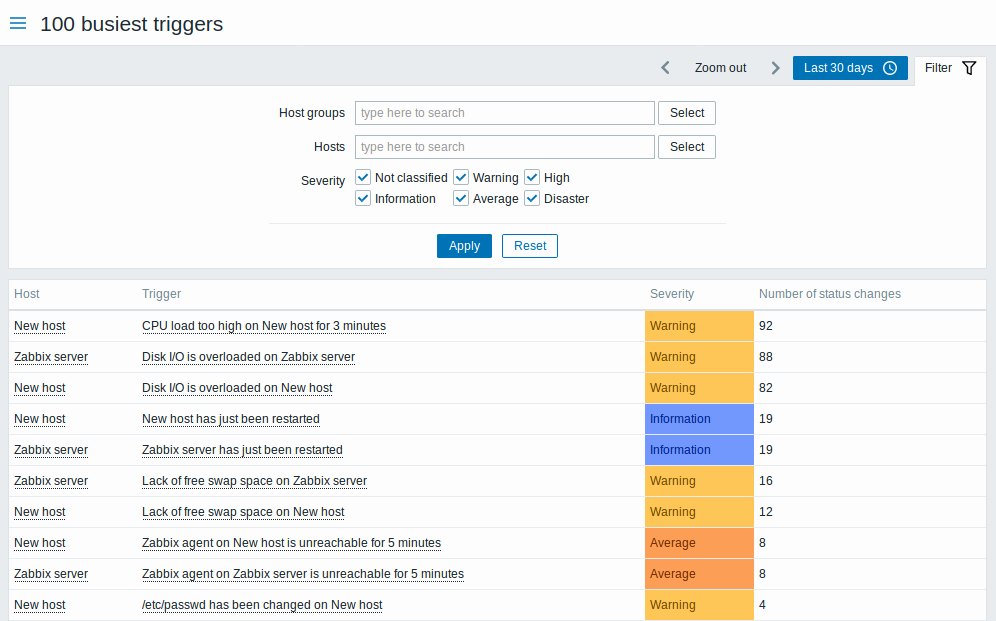
Fonte: Site oficial Zabbix
2. Defina um grupo de hosts e etiquetas de disponibilidade/recursos para as triggers que definem a indisponibilidade do serviço naquele grupo. Depois crie o indicador de disponibilidade em Serviços, dessa forma sempre que uma trigger for acionada até sua recuperação o zabbix fará o cálculo de SLI e te entregará o relatório SLA.
**Dica:** Você poderá definir o SLO para que ele te entregue o Error budget também (visualizo eles no Grafana). E é bem comum que você não tenha um SLO de primeira, para isso, calcule o quanto esse serviço ficou disponível nos últimos 30 dias pelo banco e terá um parâmetro. SLOs altos sugerem mais investimento em disponibilidade, ou seja maior custo para serem operantes a maior parte do tempo.
Fórmula:
SLI (%) = (Tempo Total − Tempo de Indisponibilidade) / Tempo Total × 100
Onde:
- Tempo Total = duração da janela analisada (ex.: mês, semana)
- Tempo de Indisponibilidade = soma dos períodos em estado de falha (downtime)
Exemplo:
Janela mensal: 30 dias = 43.200 minutos
Indisponibilidade: 40 minutos
Grafana OSS (PromQL)
MTTR
Para MTTR, essa consulta busca dados da tabela alert_instance (Grafana Alerting), filtra pelo rule_org_id selecionado no dashboard e pelo intervalo de tempo do painel ($__timeFrom() e $__timeTo()), calcula uma duração em segundos e extrai labels importantes para montar a tabela no Grafana.
Ps.MySQL
Ela retorna uma linha por “registro” agrupado com: • Nome do alerta (label alertname) • Identificação do alvo (label host/instance/vm_name) • Estado do alerta (current_state) • Início/fim (timestamp) • Duração (segundos e formato legível) • Contagem de ocorrências (qtd_alertas) dentro do agrupamento
WITH TimeData AS (
SELECT
rule_org_id,
current_state,
current_state_since,
current_state_end,
(COALESCE(current_state_end, extract(epoch FROM now())) - current_state_since) AS diff_seconds,
labels::jsonb AS json_data
FROM
alert_instance
WHERE
rule_org_id = $rule_org_id
AND (
(current_state_since >= extract(epoch FROM timestamp $__timeFrom())
AND current_state_since <= extract(epoch FROM timestamp $__timeTo()))
OR
(COALESCE(current_state_end, extract(epoch FROM now())) >= extract(epoch FROM timestamp $__timeFrom())
AND COALESCE(current_state_end, extract(epoch FROM now())) <= extract(epoch FROM timestamp $__timeTo()))
)
),
ExtractedData AS (
SELECT
rule_org_id,
current_state,
current_state_since,
current_state_end,
diff_seconds,
(SELECT value->>1
FROM jsonb_array_elements(json_data) AS value
WHERE value->>0 = 'alertname') AS alert_name,
COALESCE(
(SELECT value->>1 FROM jsonb_array_elements(json_data) AS value WHERE value->>0 = 'host'),
(SELECT value->>1 FROM jsonb_array_elements(json_data) AS value WHERE value->>0 = 'instance'),
(SELECT value->>1 FROM jsonb_array_elements(json_data) AS value WHERE value->>0 = 'vm_name'),
'Sem host'
) AS host_name
FROM TimeData
)
SELECT
alert_name,
host_name,
current_state,
COUNT(*) AS qtd_ocorrencias
FROM ExtractedData
GROUP BY
alert_name,
host_name,
current_state
ORDER BY
qtd_ocorrencias DESC;
Disponibilidade
Em promQL, você pode montar a fórmula com as métricas e definir sua regra:
sum(rate(http_requests_total{job="meu-servico",status!~"5.."}[5m]))
/
sum(rate(http_requests_total{job="meu-servico"}[5m]))
* 100
E assim você pode começar a brincar com fogo e interpretar estrategicamente.