Padronização e Automação de Ambientes Grafana em Alta Escala com HA, LDAP e API
A adoção do Grafana como solução de visualização centralizada é uma escolha comum em ambientes corporativos. No entanto, escalar para centenas de unidades (estabelecimento) requer uma abordagem arquitetônica e operacional padronizada. Neste post, detalhamos uma implantação de Grafana com alta disponibilidade, autenticação LDAP e provisionamento automatizado para +200 estabelecimentos, incluindo dashboards e fontes de dados via API.
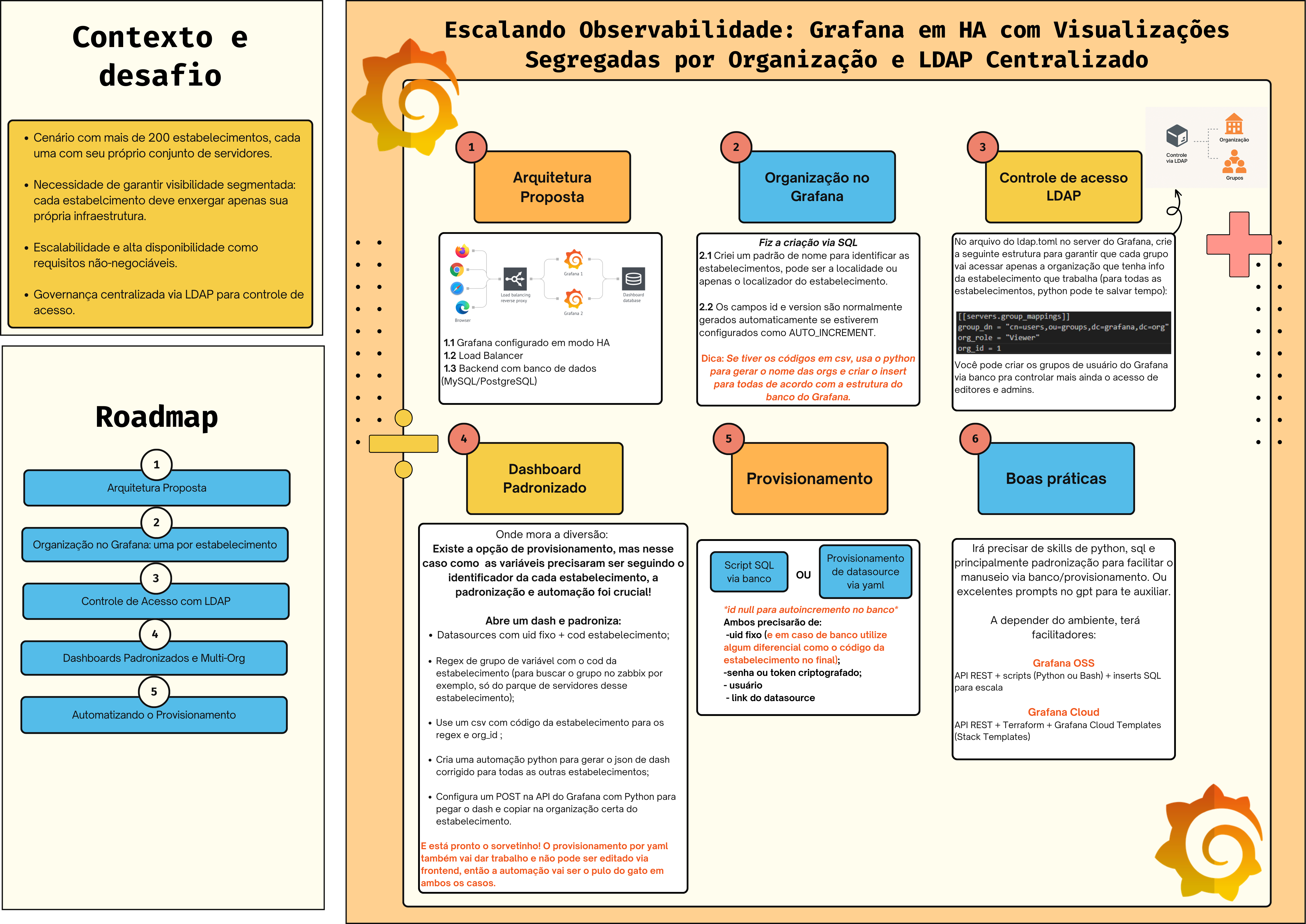
1. Grafana em alta disponibilidade (HA)
Para garantir resiliência e continuidade de serviço, a implantação foi realizada com:
- Instâncias Grafana em load balancer (modo stateless);
- Banco de dados MySQL externo compartilhado para estado e sessão;
- Diretório de plugins compartilhados via NFS;
- Monitoramento do próprio Grafana via dashboards internos.
Desenho de implantação:
[Usuário] → Load Balancer → [Instância Grafana A/B] → MySQL + NFS Plugins
2. Autenticação LDAP para estabelecimentos
O Grafana foi configurado para autenticação contra Active Directory (LDAP), com regras que direcionam o usuário automaticamente para a organização correta baseada no grupo do AD:
[[servidores]]
host = “ad.corp.local”
bind_dn = “CN=ldap_reader,OU=Serviços,DC=local”
bind_password = “senha”
…
[[servers.group_mappings]]
group_dn = “CN=estabelecimento1,OU=Estabelecimentos,DC=dnslocal”
org_id = 1
org_role = “Visualizador”
Cada estabelecimento possui seu grupo de usuários e organização dedicada.
3. Automação para criação de estabelecimentos, fontes de dados e plugins utilizando scripts python e comandos SQL diretamente no banco do Grafana, foi realizado:
Criação de organizações em lote (INSERT INTO estabelecimento);
Associação de datasources por estabelecimento (Zabbix + TestData) com UID fixo padronizado:
-
uid_zabbix_estabelecimentoXXX
-
Ativação do plugin Zabbix App via plugin_setting com enabled=1.
4. Provisionamento de dashboards via API com UID e grupo padronizados para manter consistência visual e funcional:
Os dashboards foram exportados e tratados com substituições em lote de:
-
Grupo variável com regex padronizado /123.*/;
-
Fontes de dados definidas por UID fixo, conforme organização;
-
Scripts Python autenticam por login/senha, alternam organização e realizam POST no endpoint /api/dashboards/db para cada JSON.
Com esse modelo:
-
A escalabilidade é garantida pela separação de organizações;
-
O gerenciamento de acesso é automático e seguro via LDAP;
-
Dashboards padronizados facilitam suporte e onboarding;
-
A alta disponibilidade assegura robustez para ambiente crítico.
Esse tipo de estrutura é ideal para grandes redes, varejo ou ambientes distribuídos. Se quiser um exemplo funcional ou clonar esse modelo, entre em contato.