Ferramentas de observabilidade: Qual e como usar?
Se você está em busca de compreender melhor algumas das principais ferramentas disponíveis no mercado para monitoramento e observabilidade, este artigo é para você.
E o melhor: não tem publi, tem experiência.
Antes de escolher qualquer ferramenta, é fundamental entender que ela deve ser vista como a cereja do bolo — ou seja, uma etapa que vem após a definição de objetivos claros, o entendimento das necessidades do seu ambiente e a promoção de uma cultura orientada a dados dentro do seu time DevOps.
É natural que surjam dúvidas como:
- Qual ferramenta é a melhor?
- Qual combinação atende melhor ao meu cenário?
- Existe uma solução universal?
- Essas perguntas me levaram a observar com mais atenção o foco principal, recursos e diferenciais de cada opção. A seguir, compartilho um resumo baseado em experiências práticas.
E diante desse ponto, nada mais comum que buscar os prós e contras da abordagem de cada uma.
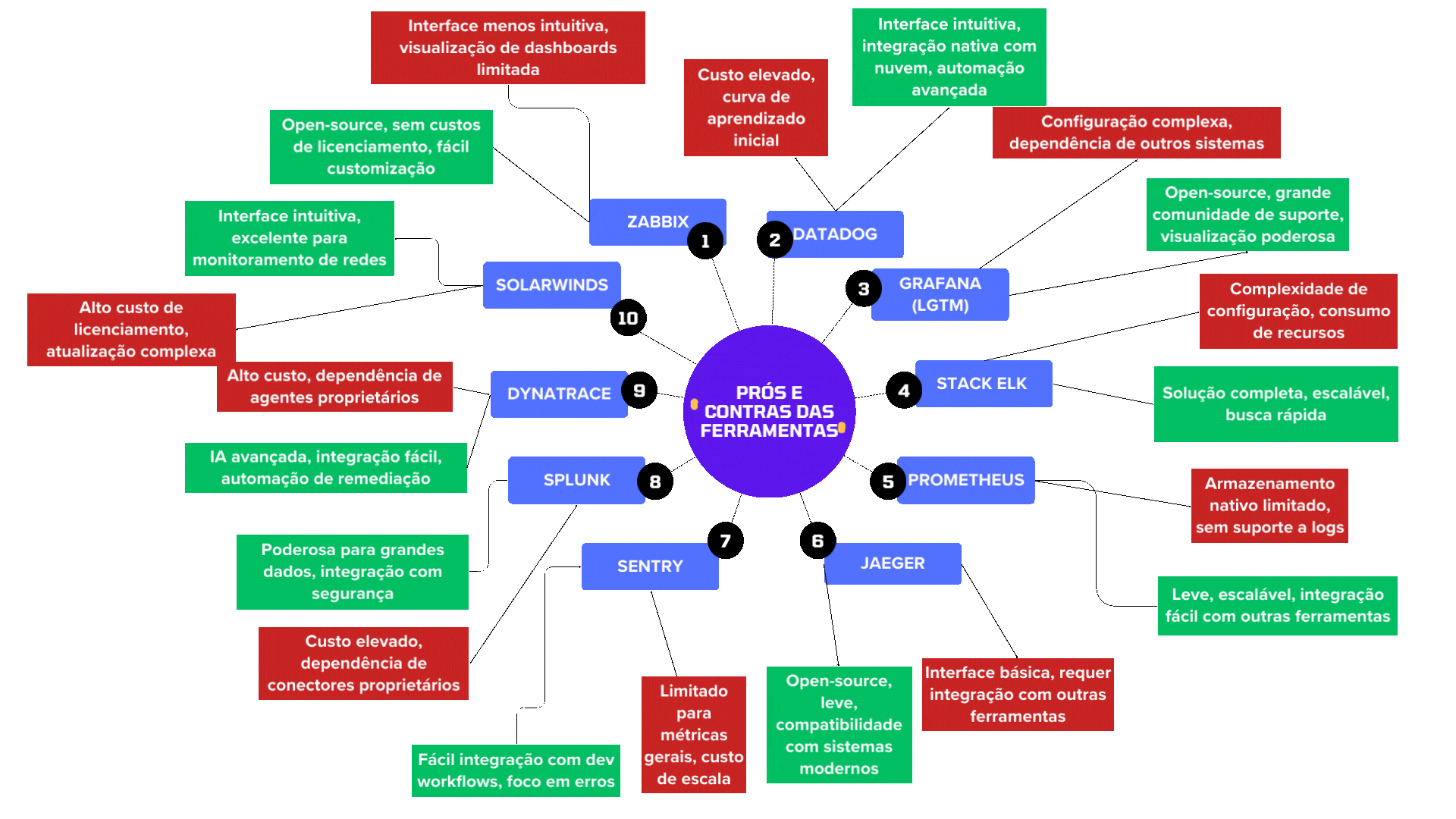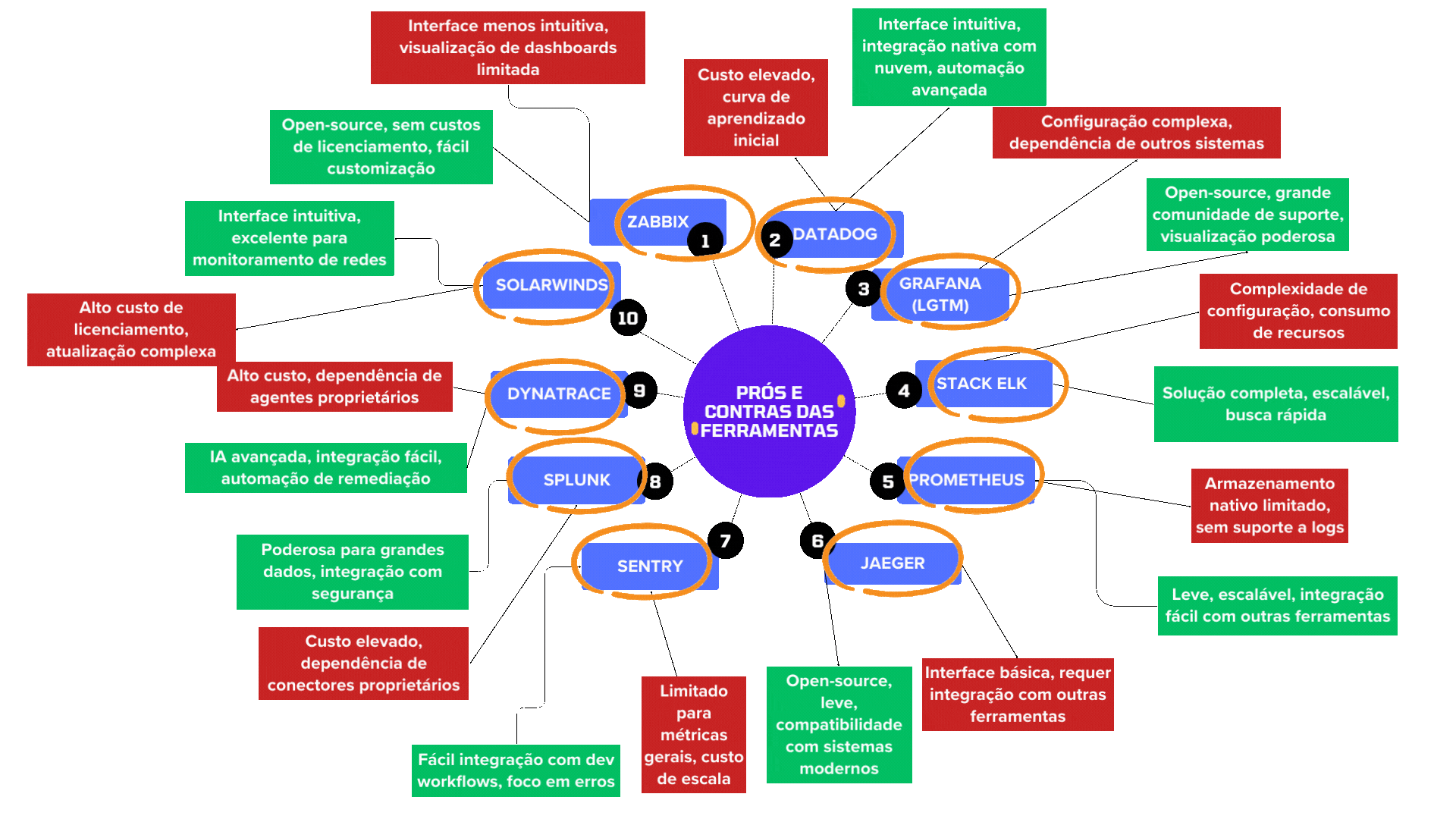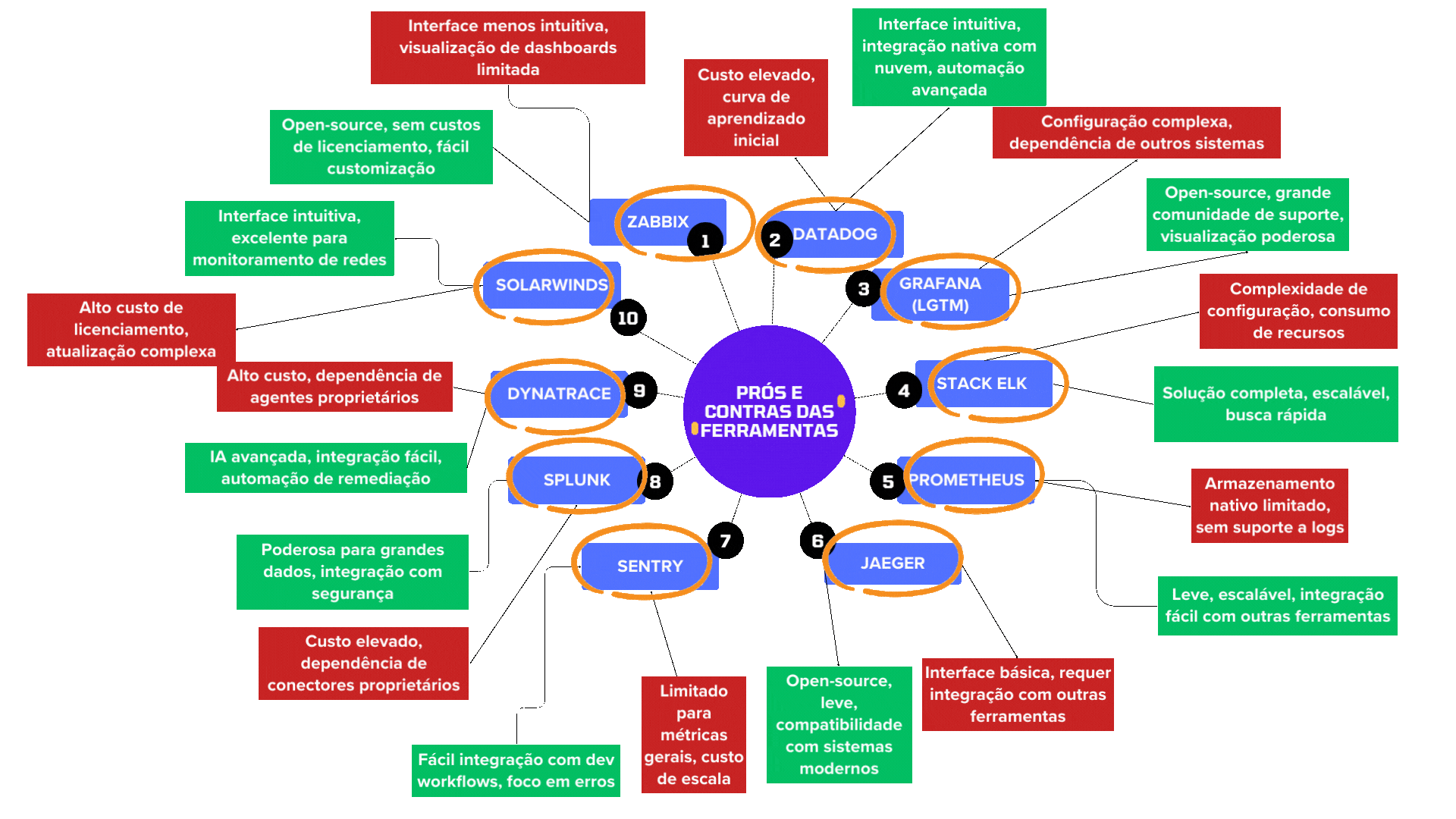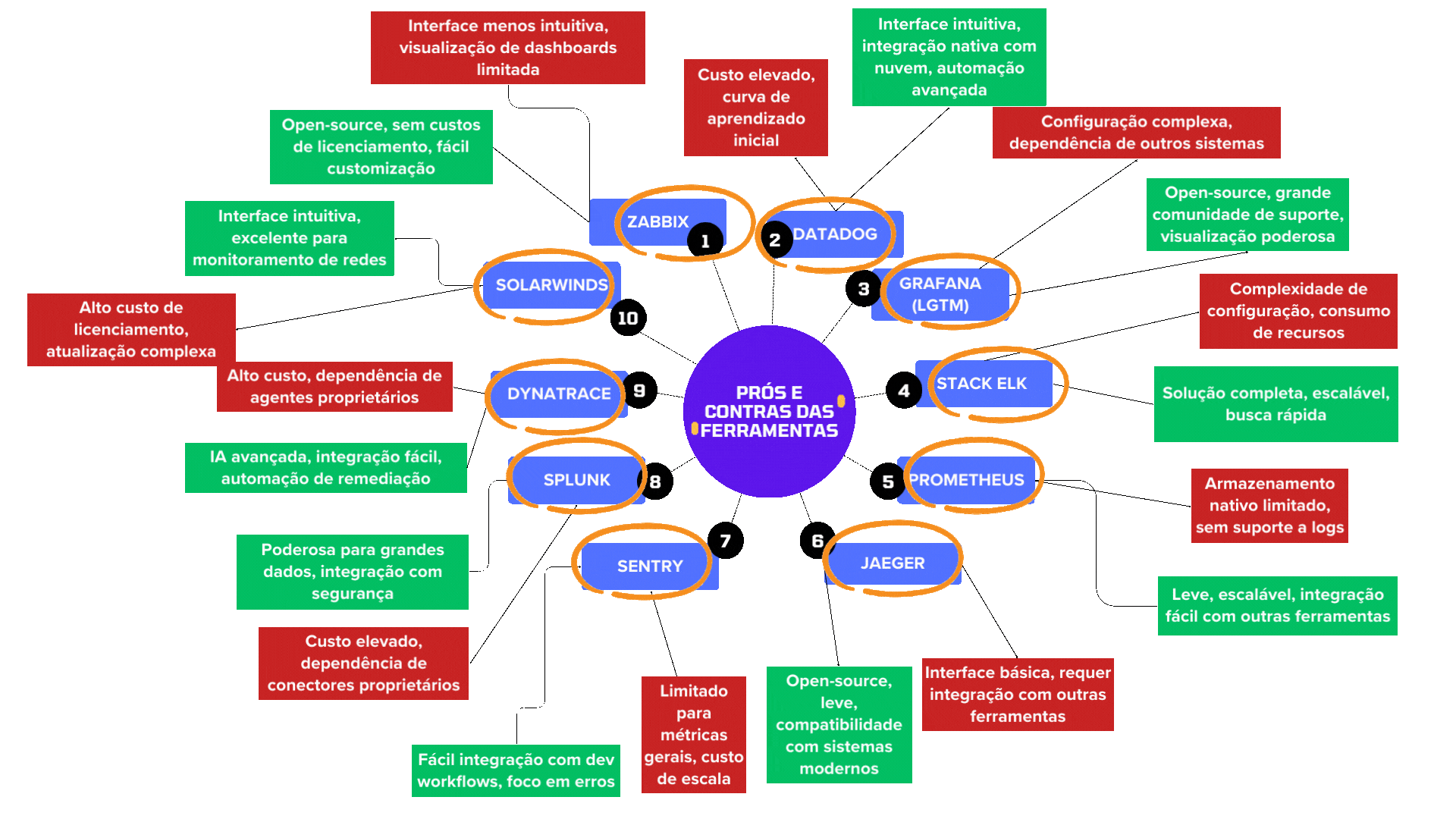
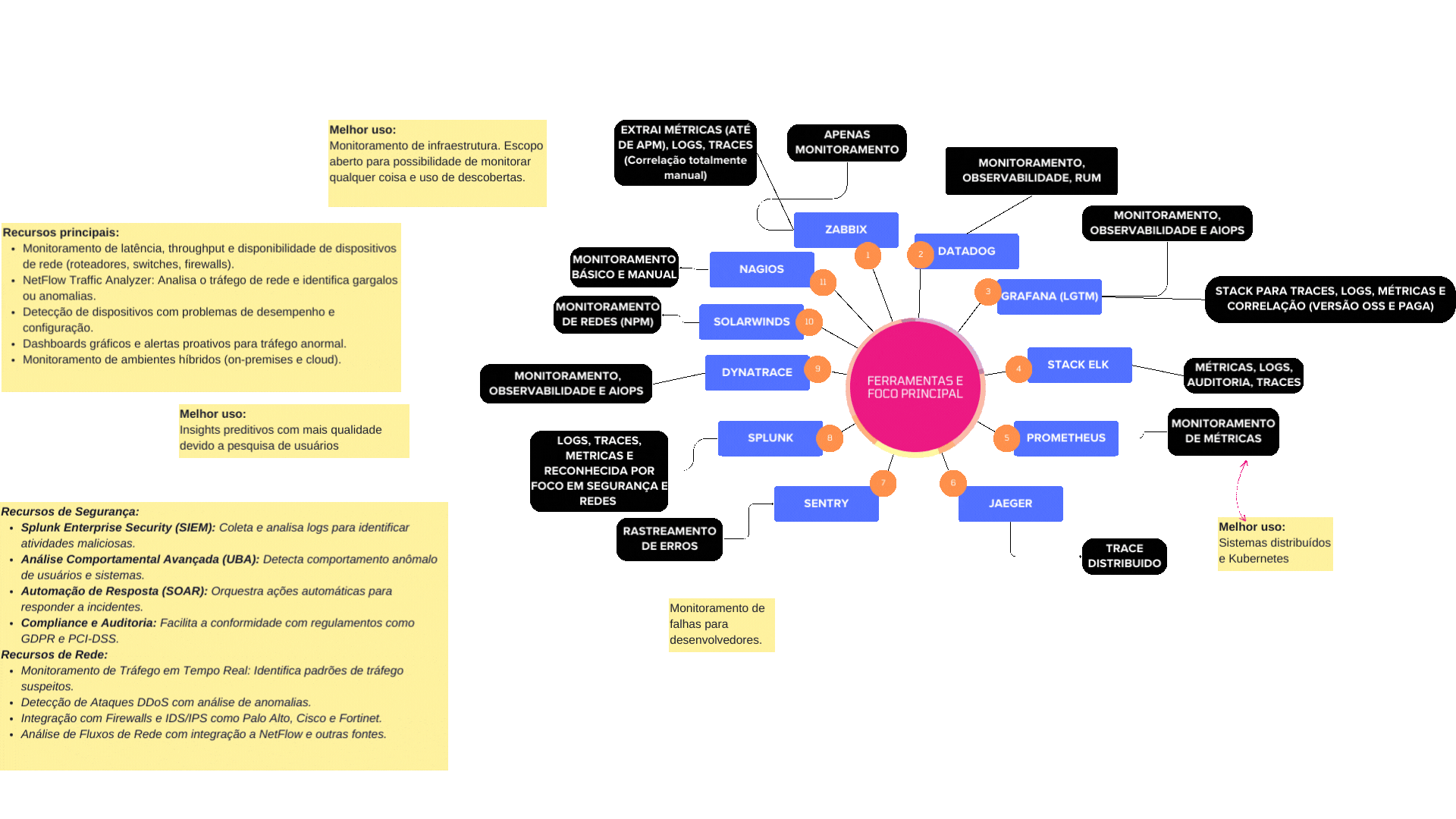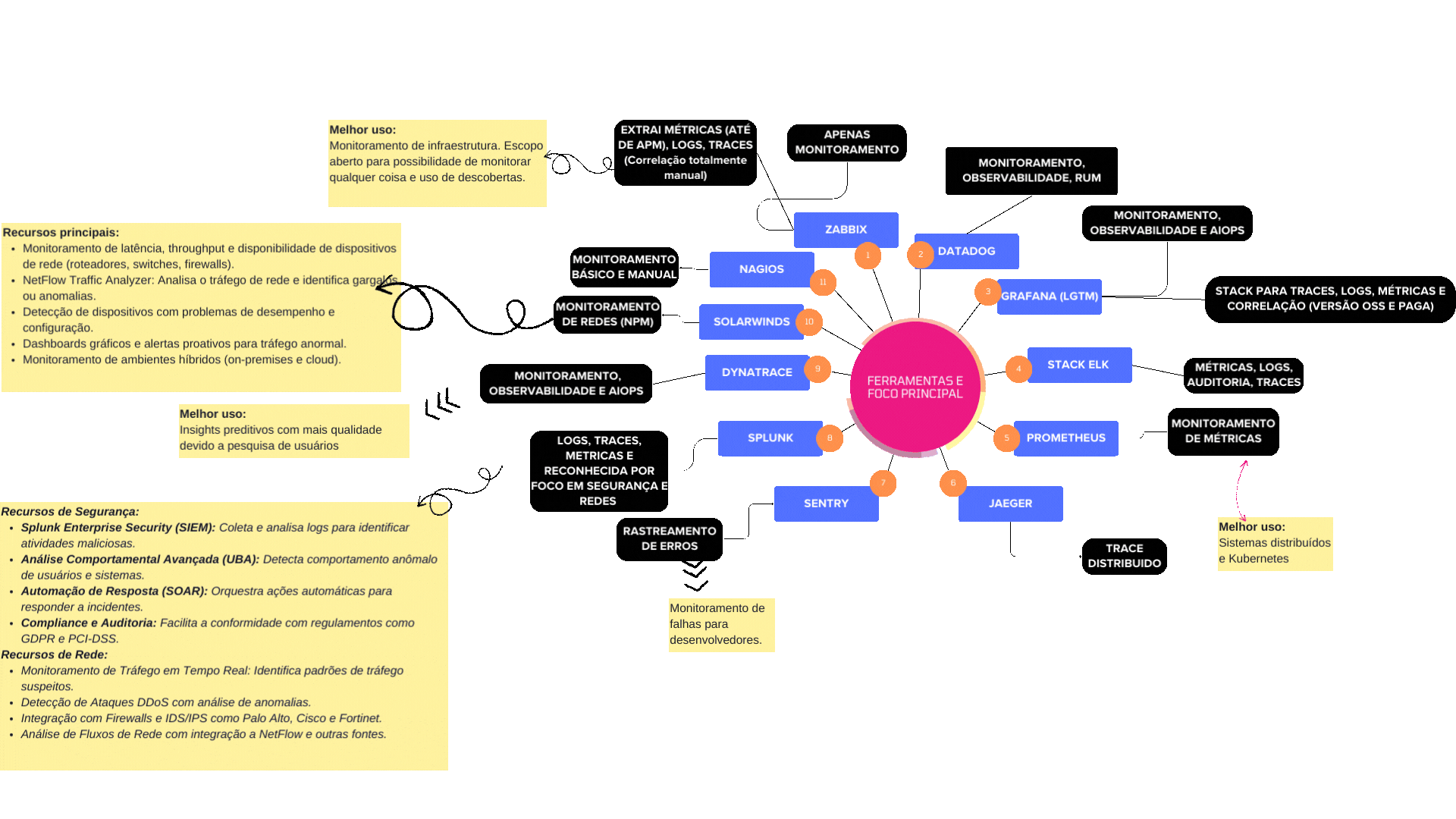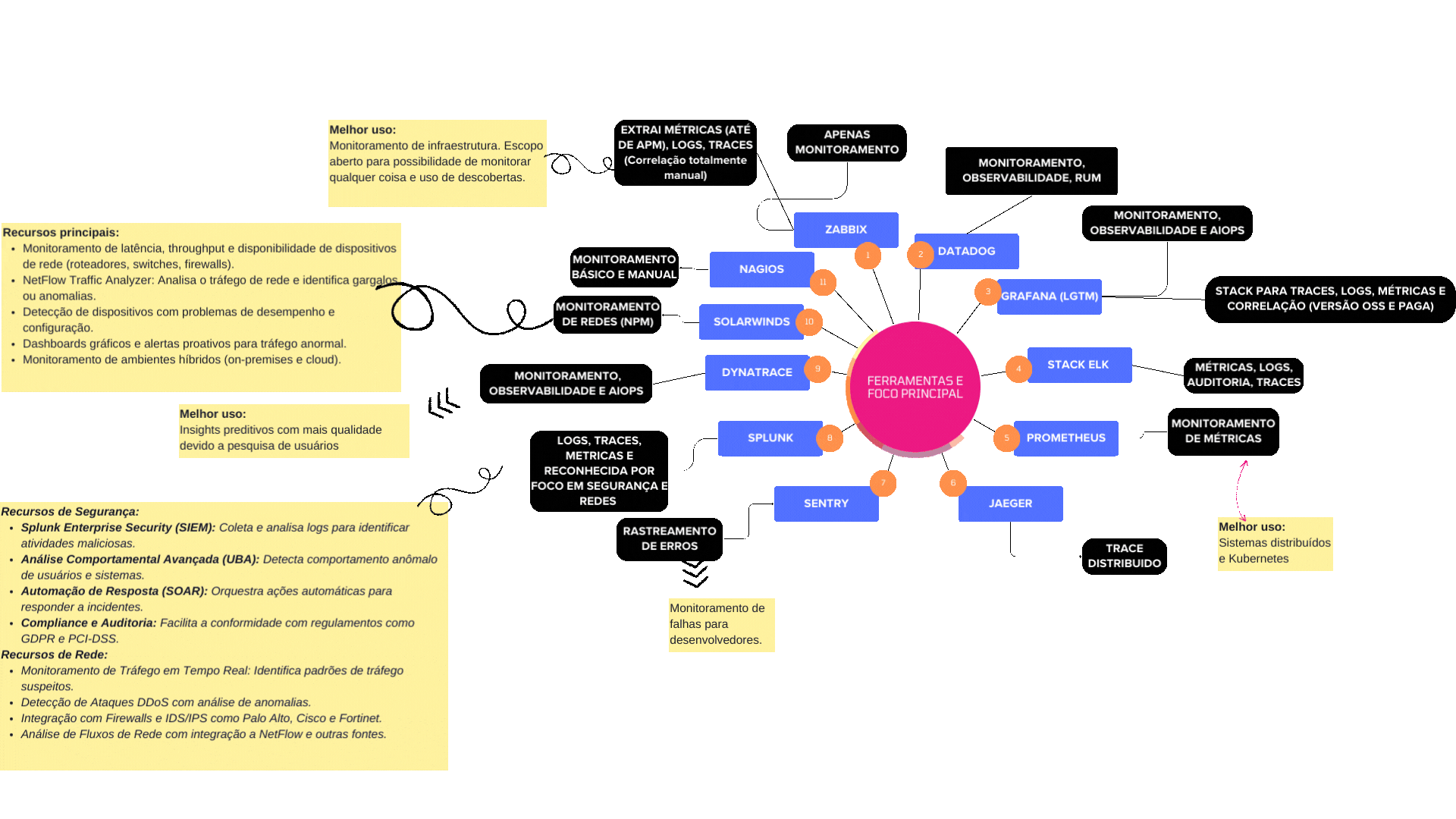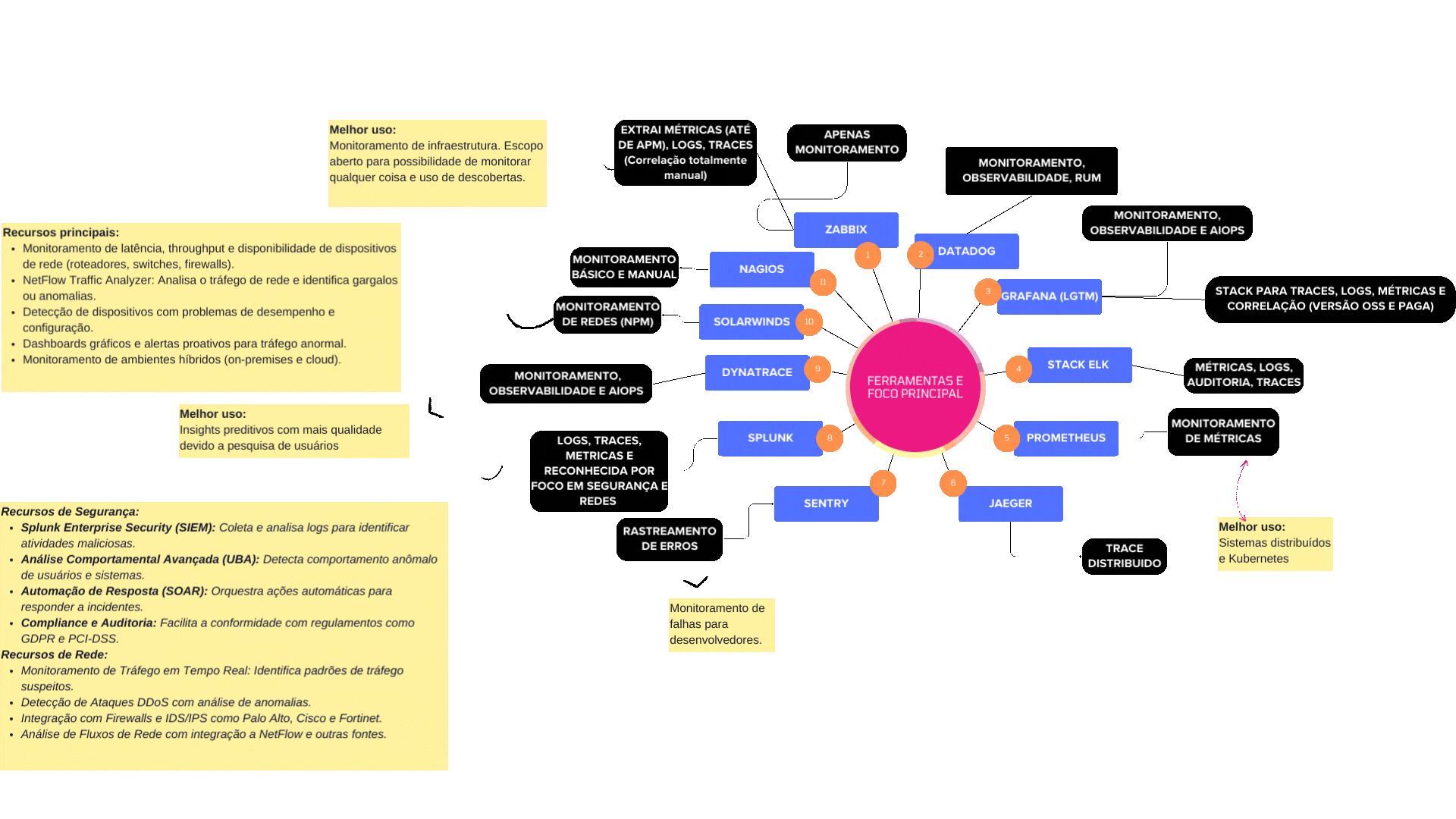
1. Zabbix
Tipo: Monitoramento. Métricas (inclusive de APM), logs, traces (com customização manual) Melhor uso: Monitoramento de infraestrutura. Escopo aberto para possibilidade de monitorar qualquer coisa e uso de descobertas. Prós: Open-source, altamente customizável Contras: Correlação manual, interface menos intuitiva
2. Datadog
Tipo: Monitoramento + Observabilidade + RUM Prós: UI intuitiva, integrações nativas, automação Contras: Custo elevado, curva de aprendizado
3. Stack Grafana (Grafana + Prometheus + Loki + Tempo)
Tipo: Observabilidade completa + AIOps Prós: Open-source, comunidade ativa, visualização poderosa Contras: Configuração inicial pode ser complexa
4. Stack ELK (Elasticsearch, Logstash, Kibana)
Tipo: Observabilidade + Auditoria **Prós: Busca poderosa, escalabilidade, machine learning Contras: Alto consumo de recursos, curva de configuração
5. Prometheus
Tipo: Monitoramento de métricas Prós: Leve, ideal para Kubernetes, escalável Contras: Sem suporte nativo a logs, armazenamento limitado
6. Jaeger
Tipo: Traces distribuídos Prós: Open-source, leve, boa integração com microservices Contras: Interface básica, depende de outras ferramentas
7. Sentry
Tipo: Rastreamento de erros Prós: Integração com o fluxo do desenvolvedor Contras: Limitado para métricas gerais, custo em escala
8. Splunk
Tipo: Observabilidade + Segurança (SIEM/SOAR) Recursos de Segurança:
- Splunk Enterprise Security (SIEM): Coleta e analisa logs para identificar atividades maliciosas.
- Análise Comportamental Avançada (UBA): Detecta comportamento anômalo de usuários e sistemas.
- Automação de Resposta (SOAR): Orquestra ações automáticas para responder a incidentes. Compliance e Auditoria: Facilita a conformidade com regulamentos como GDPR e PCI-DSS.
Recursos de Rede:
- Monitoramento de Tráfego em Tempo Real: Identifica padrões de tráfego suspeitos.
- Detecção de Ataques DDoS com análise de anomalias.
- Integração com Firewalls e IDS/IPS como Palo Alto, Cisco e Fortinet.
- Análise de Fluxos de Rede com integração a NetFlow e outras fontes.
Prós: Visão empresarial, segurança e redes
Contras: Custo alto, conectores proprietários
9. Dynatrace
Tipo: Observabilidade + AIOps + Inteligência Melhor uso: Insights preditivos com mais qualidade devido a pesquisa de usuários Prós: IA nativa, remediação automática, experiência rica Contras: Alto custo, agentes proprietários
10. SolarWinds
Tipo: Monitoramento de redes
Recursos principais:
- Monitoramento de latência, throughput e disponibilidade de dispositivos de rede (roteadores, switches, firewalls).
- NetFlow Traffic Analyzer: Analisa o tráfego de rede e identifica gargalos ou anomalias.
- Detecção de dispositivos com problemas de desempenho e configuração.
- Dashboards gráficos e alertas proativos para tráfego anormal.
- Monitoramento de ambientes híbridos (on-premises e cloud).
Prós: Visão clara de redes híbridas e latência
Contras: Custo elevado de licenciamento
11. Nagios
Tipo: Monitoramento básico
Prós: Open-source e confiável
Contras: Manual, sem observabilidade moderna
A implantação e combinação dessas ferramentas proporciona muitos resultados bons quando o objetivo é ser agnótisco e não se prender a verdors.
Vale salientar, que a maioria delas tem agents ou formas de coleta nativas, e quando o cliente decide não utilizar mais, existe um retrabalho nas instrumentações.
Nesse contexo, atualmente, a solução de framework Opentelemetry tem sido adotada para realizar coletas e enviar para os backends dessas ferramentas visando maior personalização e flexibilidade.
Sempre uso como referência o exemplo de Marilya Gutierrez, em que ele é considerado o “Cabo C” das integrações, enfatizando a possibilidade de integração com todas as ferramentas como coletor universal. E, apesar de necessitar inicialmente de uma maturidade de conhecimento, tem o suporte da comunidade e auxílio de ferramentas que facilitam inicialmente sua implantação como o Grafana Beyla.
Hora da dica!
*O Grafana Beyla é um agente leve de instrumentação automática (eBPF-based) desenvolvido pela Grafana Labs, projetado para coletar métricas e traces de aplicações sem que você precise modificar o código da aplicação.*
Ele é focado especialmente em:
- Coleta automática de métricas RED (Rate, Errors, Duration) de serviços HTTP/gRPC.
- Coleta de traces distribuídos com suporte ao OpenTelemetry (OTel).
- Funcionamento baseado em eBPF (extended Berkeley Packet Filter), que permite inspeção do tráfego na camada de rede sem impacto significativo na performance da aplicação.
- Implantação fácil via daemonset em clusters Kubernetes.
- Ideal para quem quer começar com OTel sem grandes dores. :)
*Abaixo criei um mapa mental que fala sobre os benefícios das integrações com o OTel.
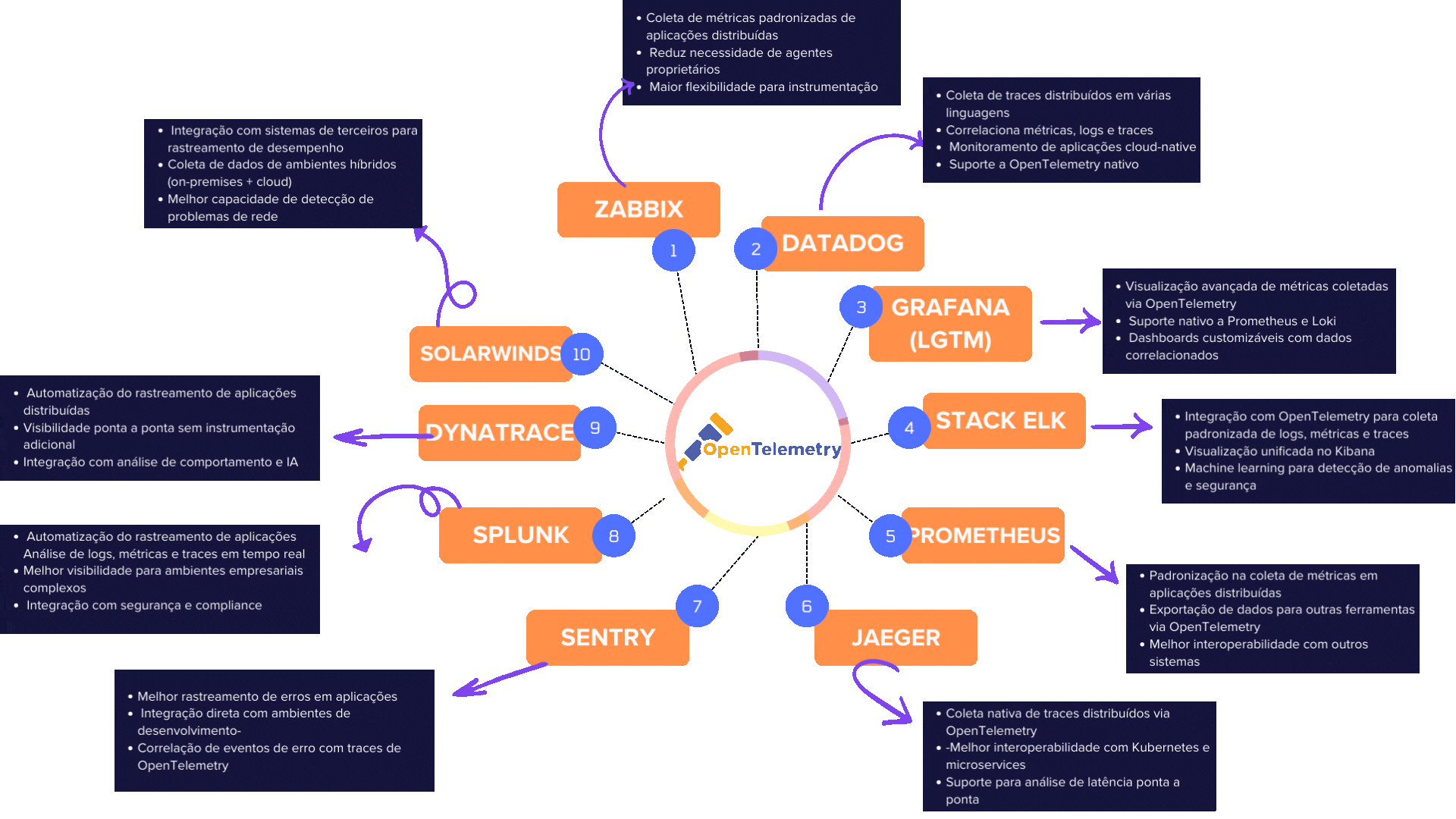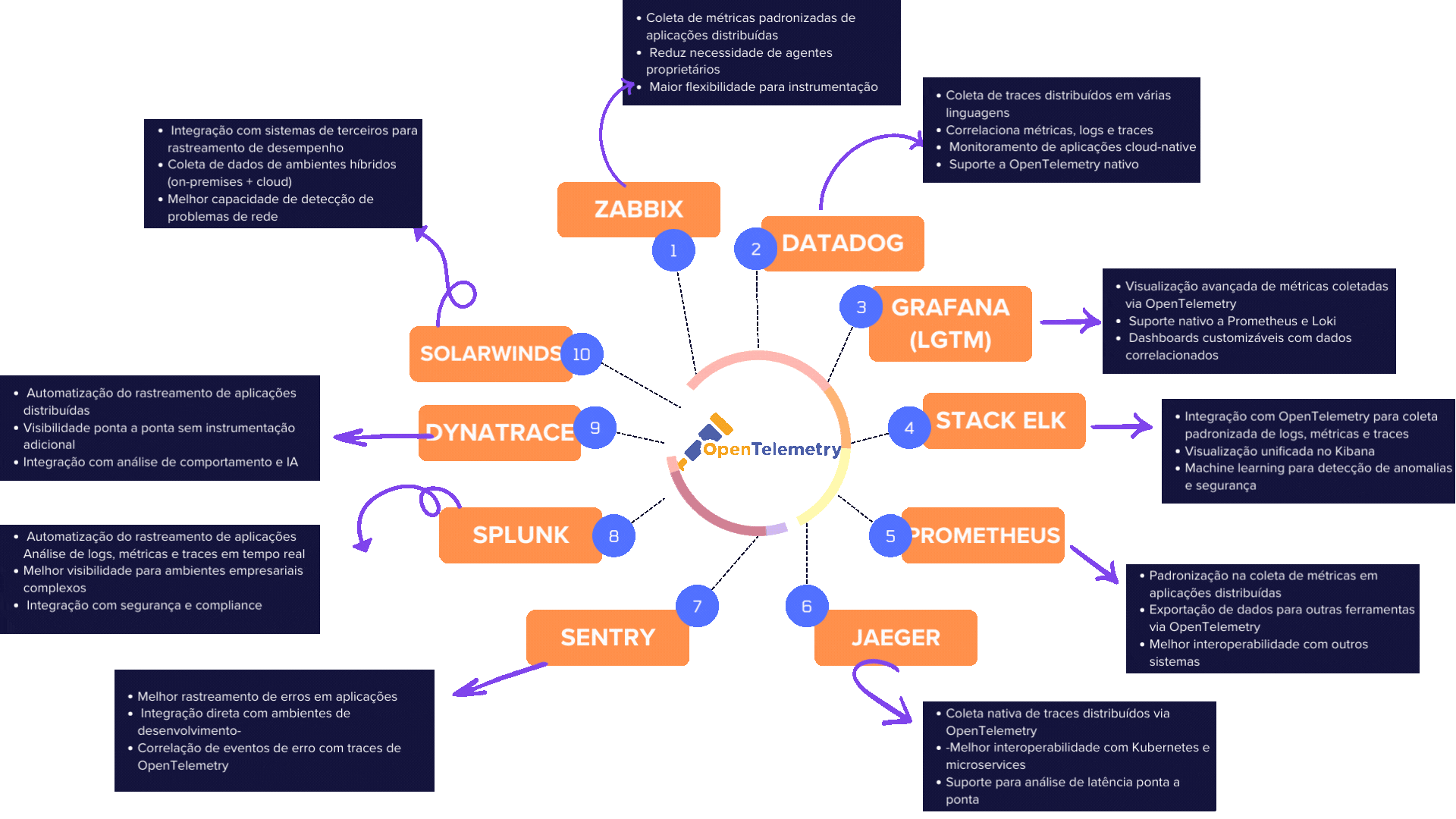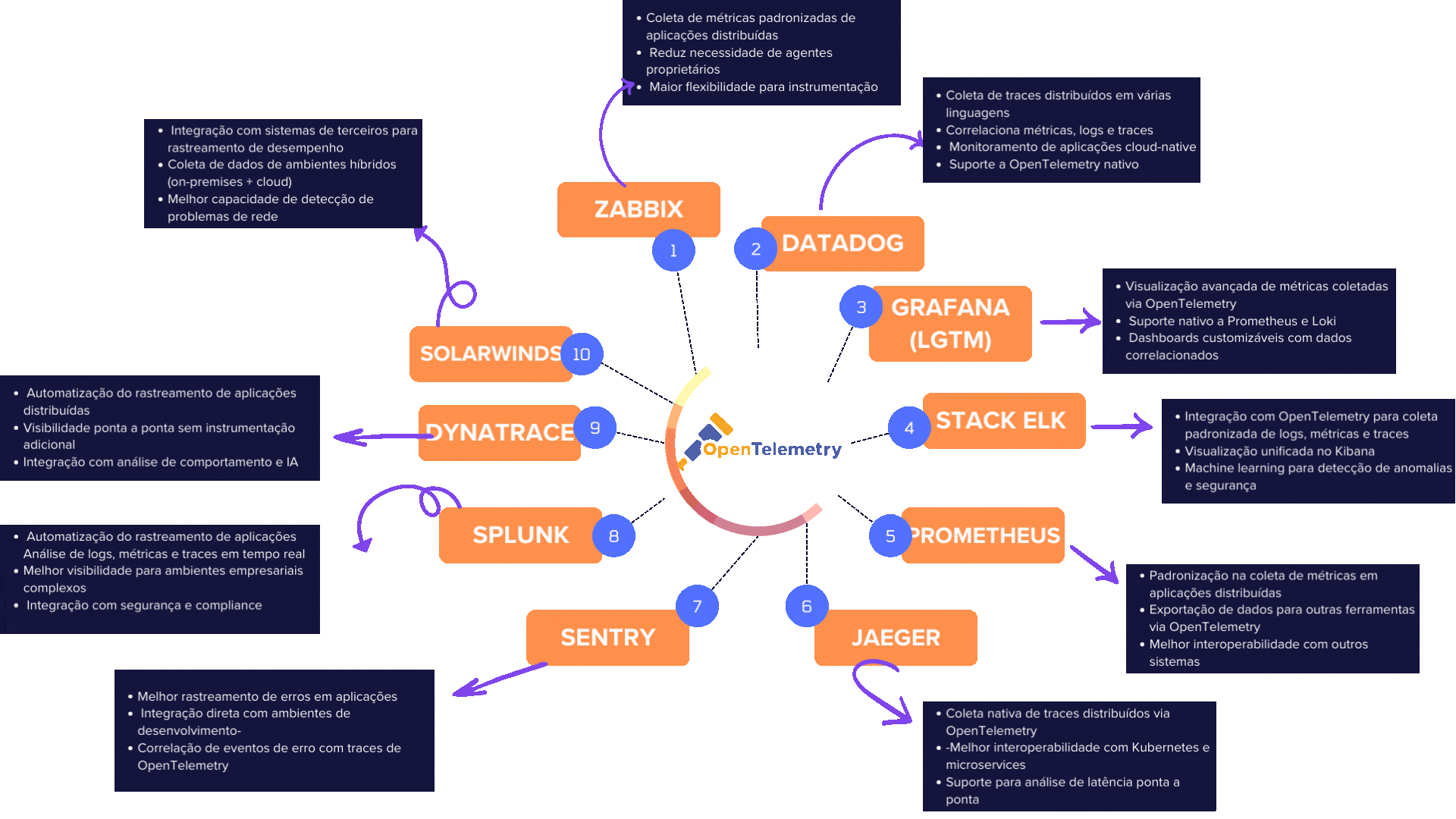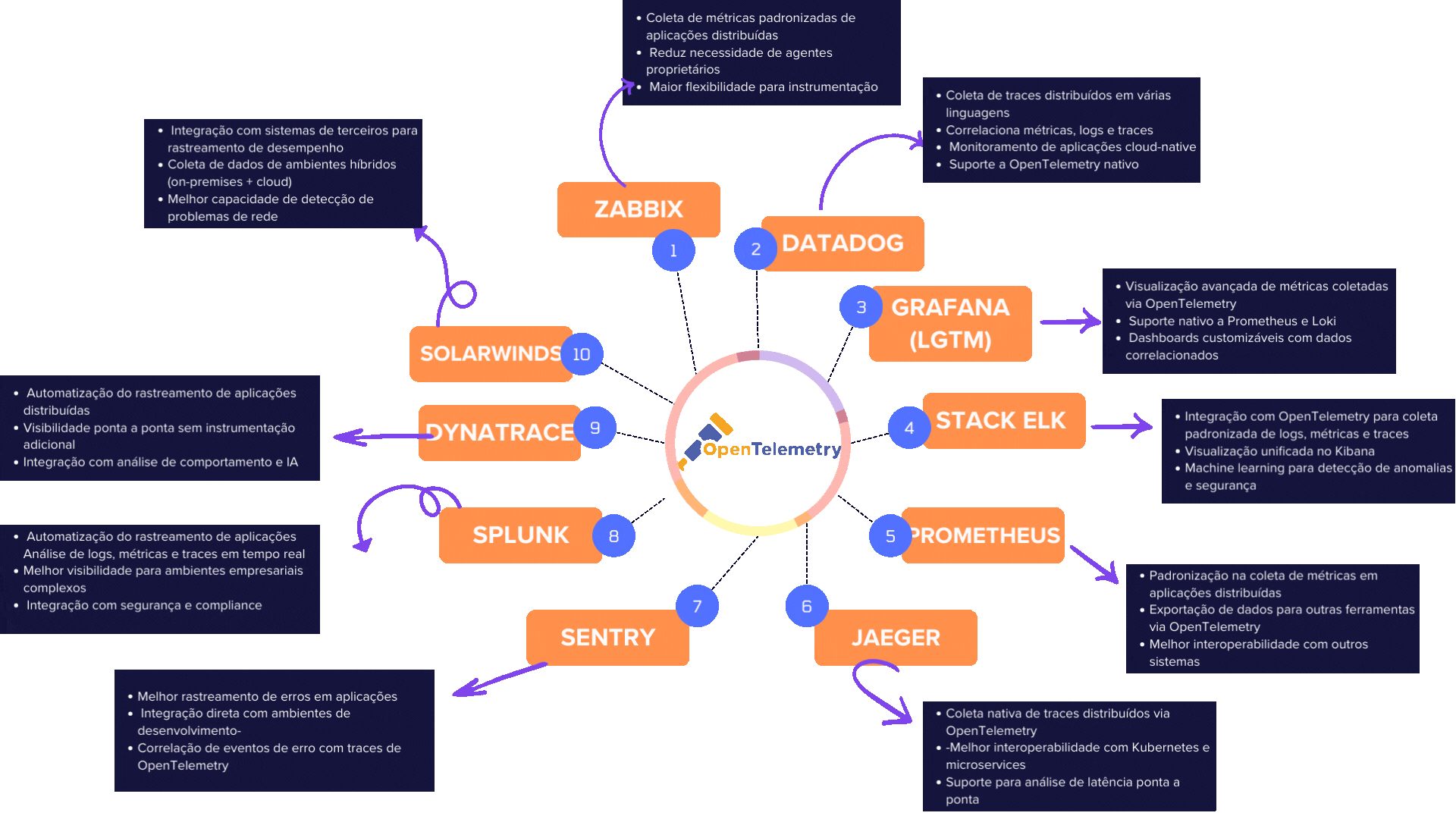
1.Zabbix
- Coleta padronizada de métricas
- Redução de dependência de agentes
- Mais flexibilidade na instrumentação
2.Datadog
- Coleta de traces distribuídos
- Correlação entre logs, métricas e traces
- Suporte nativo ao OpenTelemetry
3.Grafana
- Dashboards com dados via OTel
- Integração com Tempo, Mimir/prometheus e Loki
- Visualizações personalizadas
4.ELK Stack
- Coleta padronizada de logs, métricas e traces
- Visualização integrada no Kibana
- Análise de anomalias com machine learning
5.Prometheus
- Padronização de métricas
- Exportação para outras ferramentas via OTel
- Boa interoperabilidade
6.Jaeger
- Traces distribuídos com OpenTelemetry
- Melhor integração com microservices
- Análise de latência ponta a ponta
7.Sentry
- Melhor rastreamento de erros
- Correlação com traces OTel
- Integração direta com fluxos Dev
8.Splunk
- Análise unificada em tempo real
- Integração com ambientes empresariais complexos
- Visibilidade avançada para segurança e compliance
9.Dynatrace
- Rastreamento automatizado com IA
- Integração com comportamento de usuário
- Análise preditiva
10.SolarWinds
- Coleta de dados híbridos (on-premises e cloud)
- Integração com terceiros via OTel
- Melhor visibilidade de redes
- Não existe uma única solução ideal. O que existe é a combinação certa, no tempo certo, com uma arquitetura aberta e sustentável.
A utilização do OpenTelemetry como coletor universal tem sido uma chave importante para quem busca flexibilidade e independência, reduzindo lock-in e otimizando resultados.
Como tem usado por aí? me conta!