Observabilidade alinhada ao negócio
Por onde começar?
É comum ainda encontrar cenários em que equipes focam exclusivamente em análises técnicas, enquanto a jornada até perguntas estratégicas ainda é longa. Questões como impacto no negócio, experiência do usuário e correlação com receita muitas vezes ficam em segundo plano.
Passos iniciais
Passo 01
Passo 02
Exemplo prático — aplicando os 5 porquês
1. Por que o sistema de autenticação está lento e falhando?
2. Por que o servidor está sobrecarregado?
3. Por que houve esse aumento inesperado nas requisições?
4. Por que a equipe de infraestrutura não ajustou a capacidade do servidor?
5. Por que não houve essa comunicação clara?
Da análise à prática
Impacto do problema
Regras de negócio
Sugestão de alertas
Alerta 01: Latência média do serviço de autenticação acima de 200 ms por mais de 5 minutos.
Alerta 02: Taxa de erros no serviço de autenticação acima de 1% em 5 minutos consecutivos.
Alerta 03: Aumento súbito no volume de requisições (+30% em 10 minutos) sem ajuste na capacidade.
Sugestão de painel
- Gráfico de latência média do serviço de autenticação ao longo do tempo
- Monitoramento da taxa de erros em percentual
- Volume de requisições por minuto
- Indicadores de capacidade do servidor (CPU, memória, conexões ativas)
- Eventos recentes, como lançamentos de funcionalidades e mudanças na infraestrutura
Tudo é processo: foco no impacto e na regra de negócio
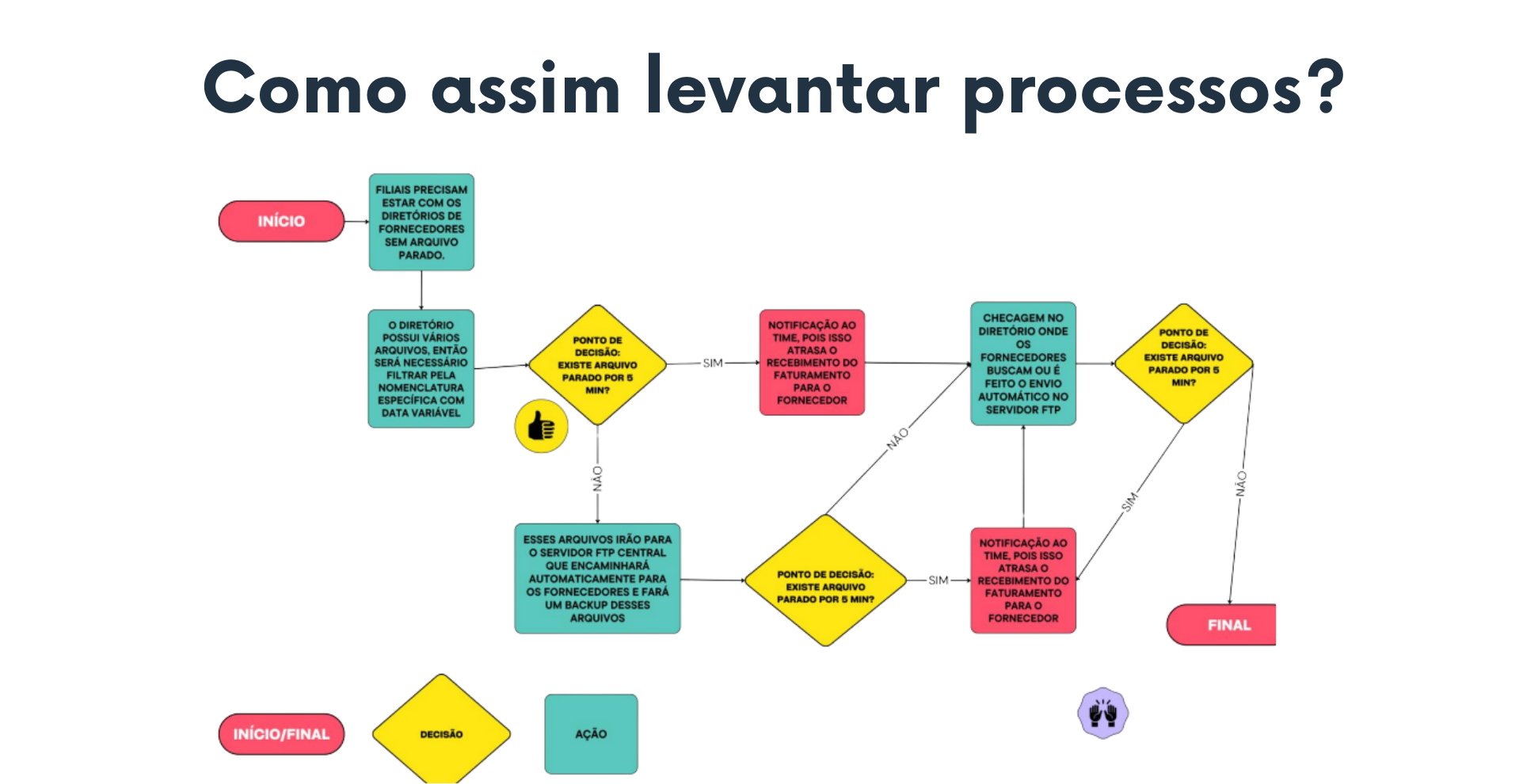
Por isso, o caminho sempre é:

Métrica técnica → Regra de negócio → Impacto, dashboard e alerta!
Caso 01: Recursos ( FinOps ama! )

Caso 02: Datas comemorativas

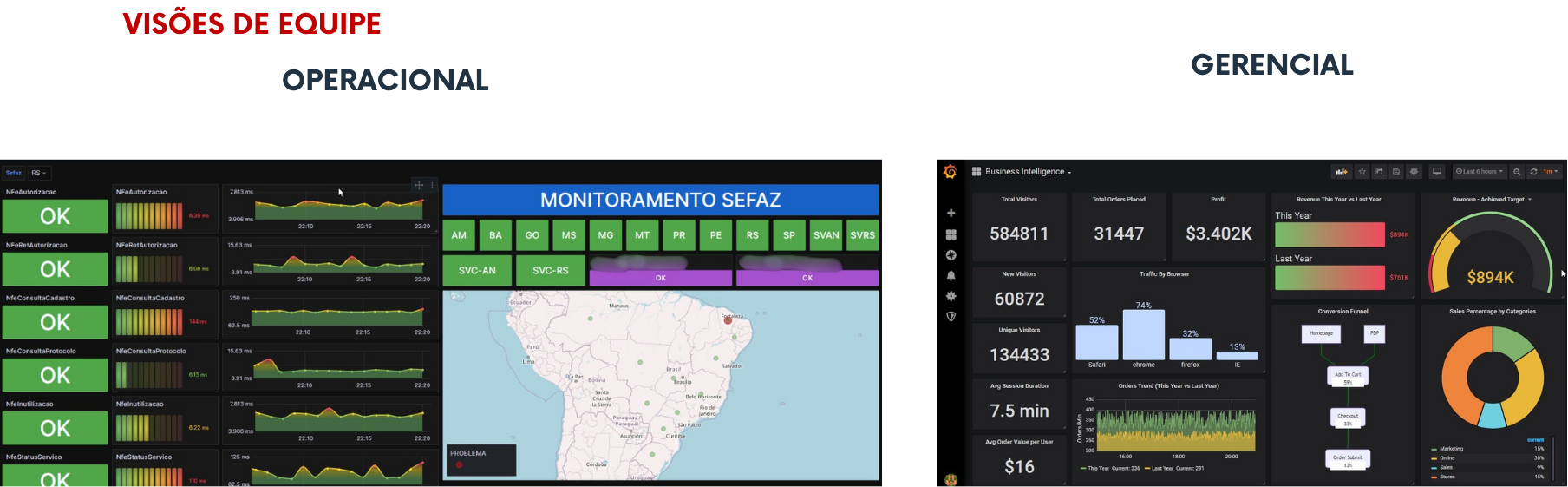
Você sabia que existem documentos explicando a funcionalidade de cada parte de um dashboard para que todos aprendam o processo?
Aqui está uma visão de equipe operacional e gerencial.
USE x RED x 4 Sinais DE OURO: Você sabe qual usar para responder sua pergunta?

O USE é composto por Utilização, Saturação e Erros. Esses indicadores aparecem no escopo da solicitação e têm seu foco em recursos (hardware e infraestrutura), sendo utilizados para identificar gargalos.
Exemplo: Uso de CPU, Fila de processos, Erro de leitura no disco.
Já o RED composto por Taxa, Erros e Duração também aparece no escopo, mas são voltados para serviços e APIs para garantir a qualidade do serviço.
Exemplo: Requisições HTTP, Requisições retorando HTTP 5xx, latência média p99 de 1,2 segundos.
Os 4 sinais de ouro são vistos na saída da solicitação.
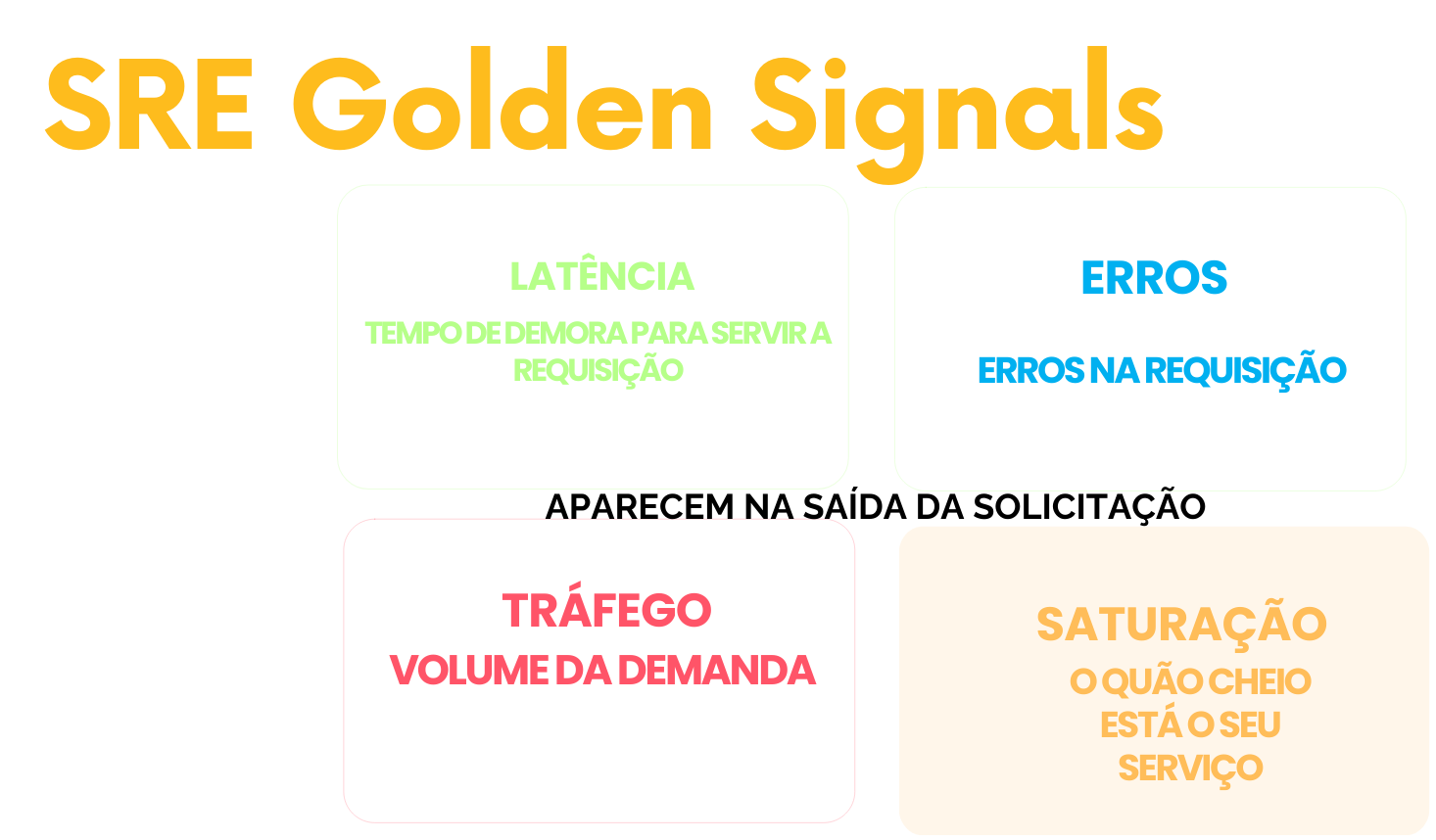
Indicadores fundamentais
- Latência: Tempo de resposta para atender a uma requisição.
- Erros: Taxa de falhas ou respostas inválidas nas requisições.
- Tráfego: Volume de requisições recebidas ou dados processados.
- Saturação: Nível de utilização dos recursos, afetando o impacto próximo do sistema está de sua capacidade máxima.
Ao partir de análises técnicas e de direção estruturadas, como os 5 motivos, conseguimos não apenas detectar falhas, mas entender seu impacto real e construir regras de negócios eficazes para alertas e visualizações.
Compreender frameworks como USE, RED e os Quatro Sinais de Ouro permite que equipes técnicas e de produto falem a mesma língua: a do impacto no cliente e no faturamento. Isso transforma painéis em ferramentas de decisão, não apenas em painéis de monitoramento.
O caminho que propus — da identificação dos problemas, passando pela demonstração com o negócio, até a criação de alertas e dashboards direcionados — é uma prática base para sair da observabilidade puramente técnica e caminhar rumo à observabilidade orientada ao valor.
Agora que você viu exemplos, frameworks e boas práticas, fica o convite: revise seus indicadores atuais.
Eles estão ajudando você a responder às perguntas certas?