Primeiros passos com observabilidade
Em minha experiência prática com clientes, incluindo treinamentos e palestras, percebo uma demanda crescente e consistente por clareza sobre monitoramento e observabilidade. Essa necessidade atravessa todos os níveis organizacionais: das equipes técnicas (Suporte, SREs, DevOps, Engenheiros de Plataforma) às lideranças (Coordenadores, Gerentes e Superintendentes).
Este artigo é uma compilação do que levo como base em minhas abordagens e formações para tornar esse tema compreensível, aplicável e estratégico.
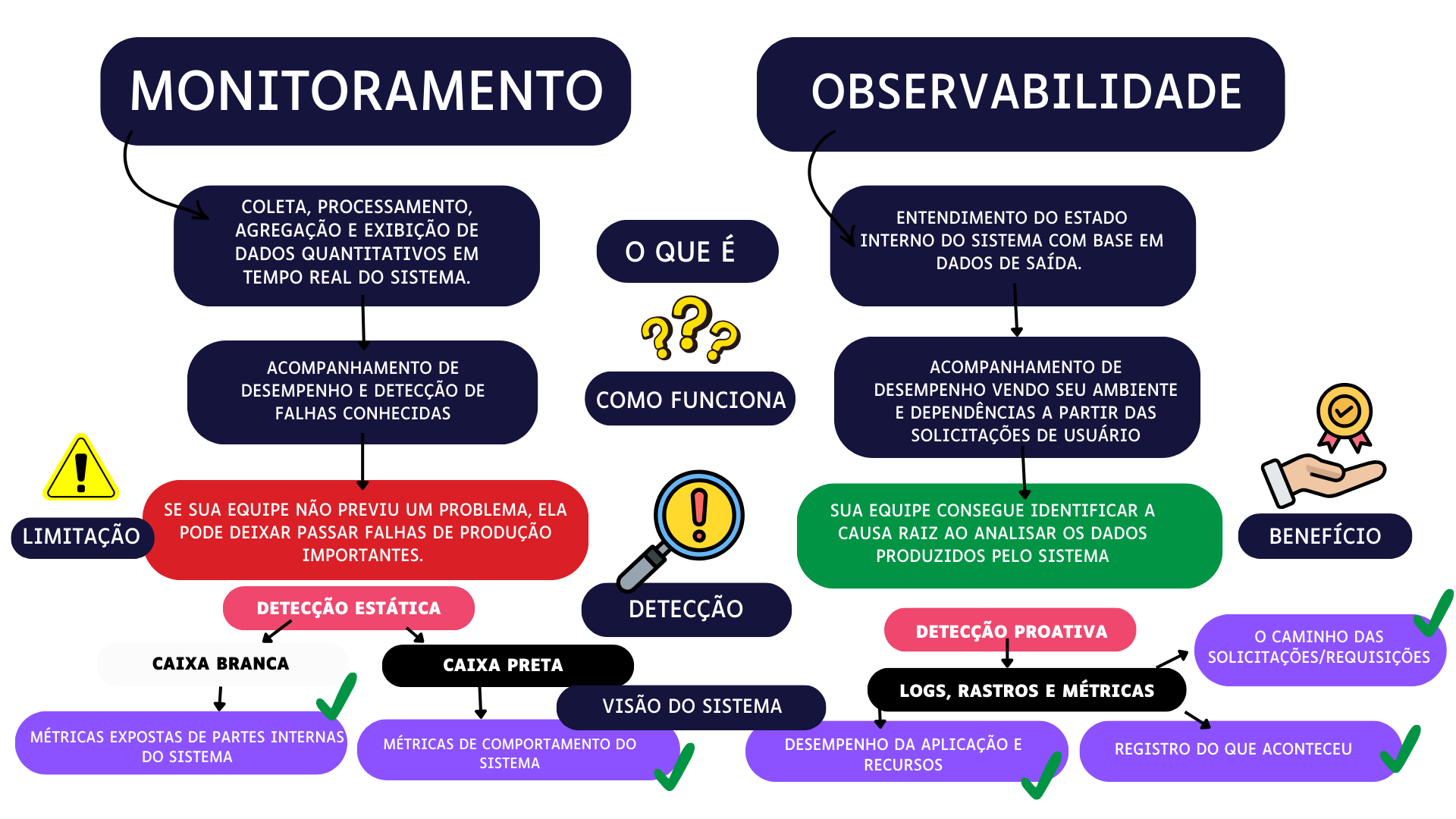
1. Monitoramento x Observabilidade
De forma direta:
- Monitoramento responde o “O quê?” e “Quando?”.
- Observabilidade responde o “Por quê?” e “Como?”.

Uma metáfora que explica tudo
Imagine que você está em uma viagem de carro. O painel do veículo mostra a temperatura do motor, o nível de combustível, e até sinaliza problemas óbvios como superaquecimento.
Mas ele não te explica por que o motor esquentou.
Seu painel avisa que o carro está sem gasolina, mas não diz que você esqueceu o tanque aberto na subida.
Já a observabilidade é como ter um mecânico com um scanner no banco do carona.
Dados que a observabilidade oferece
- Temperatura do motor (métrica tradicional).
- Histórico de rotas: 1h subindo uma serra em marcha lenta.
- Câmbio na marcha errada forçando o motor.
- Óleo vencido há 20.000 km.
- Clima externo a 35ºC com trânsito parado.
Diagnóstico
- Óleo degradado reduziu a lubrificação.
- Marcha errada aumentou o atrito.
- Falta de ventilação impediu o resfriamento.
Impacto: Se ignorado, causaria uma falha de R$15.000.
Ação Estratégica: Trocar o óleo + revisar sistema de resfriamento.
2. O que compõe a observabilidade?
A observabilidade conecta e interpreta três pilares fundamentais:
Logs: registros de eventos e ações (ex: too many requests, erros de autenticação).
Traces: rastreamento de requisições ponta a ponta (ex: uma chamada do frontend que ativa 5 microserviços).
Métricas: indicadores quantitativos de recursos (ex: CPU, memória, latência, falhas de rede).
3. Ferramentas são o fim, não o começo: Que passos seguir para ter observabilidade em meu negócio?
1. Cultura orientada a dados
Antes de qualquer ferramenta, o mais importante é a mentalidade da equipe. Qualquer sistema coleta dados, mas só um time consciente interpreta, questiona e age sobre eles. Sem isso, você só terá números soltos em dashboards.
É importante que haja uma definição de pontos críticos para ter visibilidade por quem toma a decisão de negócio (Dias de maior venda, promocionais, penalizações) e tecnicamente (quem vai escalar, colocar recurso, entrar na sala de crise e agir quando o sistema cai). Essa é a principal conversa para definir o que precisa ser aumentado/limitado e qual a estratégia usada quando houver incidente.
Isso já cria um processo a ser seguido. Com essa conversa já podemos buscar SLA(Quais penalizações a indisponibilidade causa), SLI (Qual a disponibilidade dos serviços que impactam o SLA), SLO (objetivo de disponibilidade alinhado ao FinOps), monitorando você tem MTTR(Recorrência dos problemas e tempo de recuperação é uma excelente métrica de negócio para definir estratégias de investimento na arquietura ou equipe), Triggers e até automação para gatilhos(ex.se for o caso de limpeza de partição).
2. Ferramentas (não comece por elas!)
Ferramentas são importantes, mas não são o ponto de partida. A escolha ideal depende dos objetivos, da maturidade do time e do orçamento. Ser agnóstico e aberto a combinações é o melhor caminho. Até mesmo para não acabar lidando com migrações e estressar o time com mudanças frequentes de estratégia.
3. Integração e visualização
É aqui que os dados se encontram. Com a integração entre fontes (dados de vários bancos e ferramntas), surgem as métricas de negócio(por exemplo o banco de faturamento e o health check de microsserviços no mesmo dashboard pode te dar insights valiosos), os alertas inteligentes, os insights em tempo real e as automações que de fato reduzem o impacto no usuário final.
4. Desafios comuns
-
Complexidade de Infraestruturas: A integração com sistemas heterogêneos exigem soluções personalizadas.
-
Volume: A volumetria de dados gerados podem sobrecarregar sistemas de armazenamento e análise. (Quem nunca teve problema com storage atire a primeira pedra)
-
Escolha de ferramenta: Análise criteriosa e combinações de soluções. (Pagar pra ser mais fácil? Spoiler: isso não existe)
-
Habilidades da equipe: É crucial ter profissionais qualificados (e promover qualificação) para implantar e gerenciar as soluções de observabilidade.
5. Quem faz o quê: DevOps ou SRE? (Observabilidade não é um cargo!)
Quando falo isso, é porque na prática esses cargos de analista e especialista SEMPRE vão exigir a carga de DevOps ou SRE para conseguir exercer os desafios junto as equipes e ambientes.
Ambos atuam com observabilidade, mas com focos distintos e complementares:
-
DevOps: Cultura de automação, entrega contínua, IaC, resposta rápida, métricas de negócio.
-
SRE: Confiabilidade operacional, escalabilidade, resiliência, mitigação de falhas, experiência do usuário.
A colaboração entre os dois perfis é o que permite a evolução do ambiente. Os dois colocam a mão na massa e tem uma forma mais estratégica, o ponto é que um irá ficar mais próximo do usuário (SRE) e o outro da infraestrutura (DevOps).
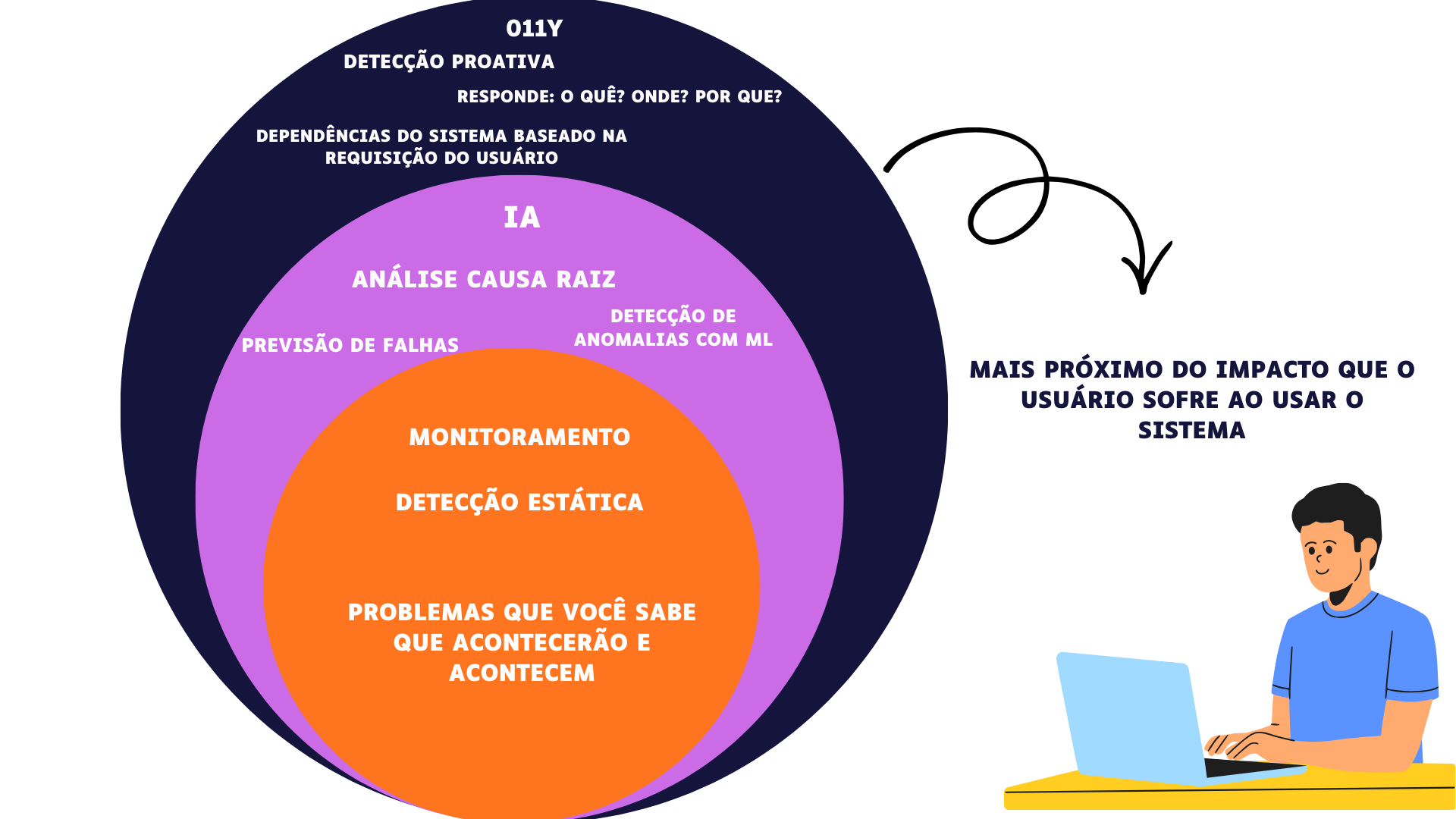
6. Níveis de maturidade: Até onde posso chegar com Observabilidade?
Nível 1: Monitorar eventos ao longo do tempo e alertar.
Nível 2: Coleta de métricas, traces e logs de forma automática e análise de problemas.
Nível 3: Estabelecimento de correlação entre sintoma e causa dos gargalos.
Nível 4: Observabilidade + AIOps e automação como solução dos problemas, traçando redes neurais desde a prévia quanto tratando anomalias de dados e comportamento.
A observabilidade não é só sobre tecnologia: é sobre compreensão profunda e ação eficaz. Ela transforma dados em contexto, e contexto em decisão. E quanto mais conectada à realidade do negócio, maior o impacto.
Quer transformar alertas em decisões estratégicas?
Compartilhe este guia com o time que ainda está olhando apenas para o painel.